
Process Synchronization and Deadlocks
Hello readers 👋,
In the last read, we discussed CPU scheduling and today, we will dive deep into Process Synchronization and Deadlocks.
The processes that are influenced by the execution of the other processes in the system are called cooperative processes. They either directly share a logical address space (code and data) or only share data through files or messages.
We will understand different mechanisms to ensure the orderly execution of cooperative processes and maintain data consistency. We will go through the concept of deadlock and understand how to avoid them.

Let's dive in!
Why Process Synchronization and Coordination is essential?
Consider a situation where several processes access and manipulate the same data concurrently, and the execution outcome depends on the particular order in which the access takes place. We must ensure that only one process can manipulate the data simultaneously. This guarantee raises the need for process synchronization and coordination among cooperating processes.
Critical Section Problem
Cooperative processes face the challenge of cooperation. The critical-section problem is to design a protocol that the processes can use to cooperate. Each process must request permission to enter its critical section. The entry section of the code implementing this request is the entry section. An exit section may follow the critical section. The remaining code is the remainder section.
Any protocol designed for critical-section problems must fulfill the following three requirements.
-
Mutual Exclusion: If process Pi executes in its critical section, then no other processes can be executed in their critical sections.
-
Progress: If no process is executing in its critical section and some processes wish to enter their critical sections, then only those processes not executing in their remainder sections can decide which will enter its critical section next, and this selection cannot be postponed indefinitely.
-
Bounded waiting: There exists a bound, or limit, on the number of times that other processes are allowed to enter their critical sections after a process requests to enter its critical section and before that, the request is granted.
Two general approaches for critical section problems in operating systems:
-
Preemptive kernels: A preemptive kernel allows a process to be preempted while running in kernel mode.
-
Non-preemptive kernels: A non-preemptive kernel does not allow a process running in kernel mode to be preempted; a kernel-mode process will run until it exits kernel mode, blocks, or voluntarily yields control of the CPU.
Synchronization in Linux
The Linux kernel is fully preemptive, so a task can be preempted when running in the kernel. Linux provides several different mechanisms for synchronization in the kernel.
-
Atomic Integer: The most straightforward synchronization technique within the Linux kernel. All math operations using atomic integers are executed without interruption.
-
Mutex locks: We use the mutex lock to protect critical regions and thus prevent race conditions. A process must acquire the lock before entering a critical section; it releases the lock when it exits the critical section. The acquire() function acquires the lock, and the release() function releases the lock.
- Spin lock: The biggest challenge is the requirement of busy waiting. While a process is in its critical section, any other process that tries to enter its critical section must loop continuously in the call to acquire(). The process "spins" while waiting for the lock to become available.
-
Semaphores: They also provide more sophisticated ways for processes to synchronize their activities. A semaphore S is an integer variable that, apart from initialization, is accessed only through two standard atomic operations: wait() and signal(). When one process modifies the semaphore value, no other process can simultaneously modify that same semaphore value.
Linux employs a straightforward method to manage kernel preemption with two simple system calls: preempt_disable() and preempt_enable(). These calls allow the system to turn kernel preemption on and off. However, kernel preemption is automatically turned off if a task currently running in the kernel holds a lock.
To implement this, each task in the system has a thread_info structure that includes a counter called preempt_count.
-
Tracking Locks
- preempt_count tracks the number of locks held by the task.
- When a lock is acquired, preempt_count is incremented.
- When a lock is released, preempt_count is decremented.
-
Kernel Preemption
- If preempt_count for the currently running task is greater than zero:
- The kernel cannot be preempted because the task holds a lock.
- If preempt_count is zero:
- The kernel can be safely interrupted.
- This is true as long as there are no outstanding calls to preempt_disable().
- If preempt_count for the currently running task is greater than zero:

Spin locks, along with turning kernel preemption on and off, are used in the kernel when a lock is held for a short duration. Semaphores or mutex locks are more appropriate for locks that need to be held longer.
Atomic Transactions
Operating systems can be viewed as manipulators of data, and we will now see some of these database-system techniques that can be used in operating systems.
The Mutual exclusion property is apparent in data consistency approaches in database systems. We like to ensure that a critical section performs work that either is performed in its entirety or is not performed at all.
Every transaction is a collection of instructions working together to achieve a single logical function. But how do we ensure that each transaction is either fully completed or leaves no trace if something goes wrong?
System Model
Every transaction must be atomic, meaning it must either be completed in its entirety or not at all. If a transaction fails, it must roll back, restoring the data to its state before it begins. A significant issue in processing transactions is preserving atomicity despite potential system failures.
-
Transaction: A collection of instructions performing a single logical function.
-
Atomicity: Ensures a transaction is fully completed or has no effect.
-
Rollback: Reverts the state of data to what it was before the transaction started if it aborts.
We must consider the properties of storage devices used for transaction data to ensure atomicity.
-
Volatile Storage: Fast access, does not survive crashes (e.g., main memory).
-
Nonvolatile Storage: Slower access, survives crashes (e.g., disks, tapes).
-
Stable Storage: Highly resilient to data loss, implemented through replication on nonvolatile storage.
Log-based Recovery
The system maintains a ledger known as the log to track all transactions and ensure atomicity. This log records every modification made by transactions on stable storage before they are applied to the actual data, a method called write-ahead logging.
-
Log Record Fields
-
Transaction name: Identifier of the transaction.
-
Data item name: Identifier of the data item.
-
Old value: Value before the write operation.
-
New value: Value after the write operation.
-
-
Special Log Records
- Mark significant events like transaction starts, commits, or aborts.
-
Recovery Procedures
-
undo(Ti): Restores old values of data updated by Ti.
-
redo(Ti): Sets new values of data updated by Ti.
-
If a system failure occurs, this log becomes the guide to undo or redo transactions, ensuring data consistency.
Checkpoints
Reduce recovery time by periodically saving system state.
-
Checkpoint Actions:
-
Write all log records in volatile storage to stable storage.
-
Write all modified data in volatile storage to stable storage.
-
Write a
record to stable storage.
-
-
Recovery Optimization: Transactions committed before the checkpoint need no further action during recovery.
Concurrent Atomic Transactions
Each transaction's atomicity must be maintained in environments with multiple active transactions. Atomicity ensures concurrent execution is equivalent to some serial order, a property known as serializability.
Serializability
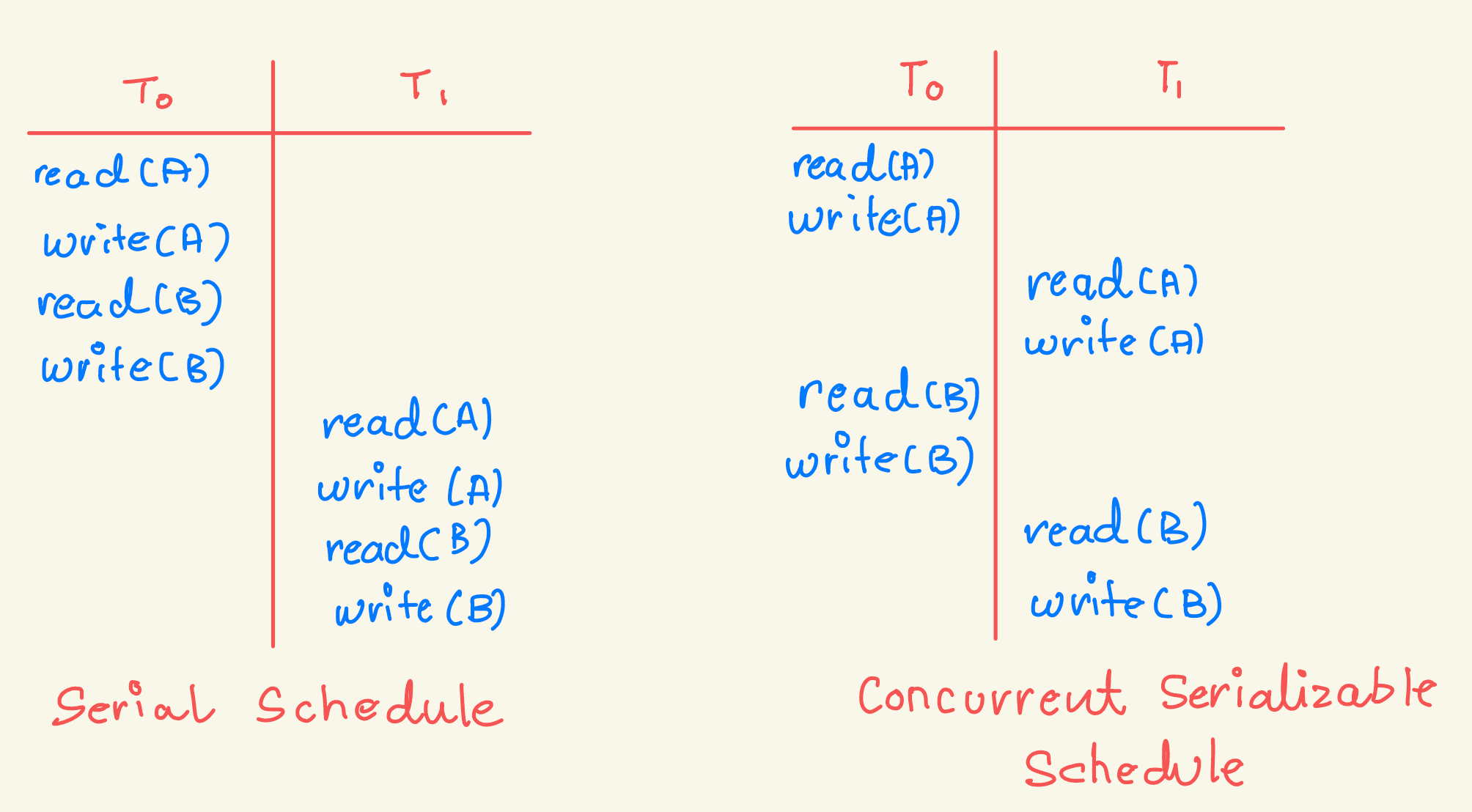
Consider a system with two data items, A and B, and two transactions, T0 and T1. If executed atomically in sequence, this is called a serial schedule, ensuring conflict serializability.
A serial schedule involves a sequence of instructions where each transaction's operations appear together—allowing transactions to overlap. This results in non-serial schedules, which can still be correct if serializable—equivalent to some serial schedule. If any schedule can be transformed into a serial schedule by a series of swaps of non-conflicting operations, the schedule is conflict serializable.
Lock Based Protocols
Lock-based protocols manage access to data items:
-
Shared lock (S): A transaction can read but not write the data item.
-
Exclusive lock (X): Allows a transaction to read and write the data item.
Transactions request locks based on their operations. The two-phase locking protocol ensures serializability:
-
Growing phase: Transactions acquire locks but do not release any.
-
Shrinking phase: Transactions release locks but do not acquire any.
While this protocol ensures serializability, it can lead to deadlock and may not produce all possible conflict-serializable schedules.
Timestamp-Based Protocols
Timestamp-based protocols order transactions in advance using unique timestamps assigned at the start. Each data item Q maintains:
-
W-timestamp(Q): Largest timestamp of any transaction successfully written to Q.
-
R-timestamp(Q): Largest timestamp of any transaction that successfully reads Q.
Transactions are processed in timestamp order, ensuring conflict serializability and freedom from deadlock:
-
read(Q): If the timestamp is less than W-timestamp(Q), the operation is rejected, and the transaction is rolled back.
-
write(Q): If the timestamp is less than R-timestamp(Q) or W-timestamp(Q), the operation is rejected, and the transaction is rolled back.
Transactions rolled back due to conflicts are assigned new timestamps and restarted. This protocol ensures conflict serializability and deadlock freedom.
Deadlocks
What are the criteria of a "Deadlock"?
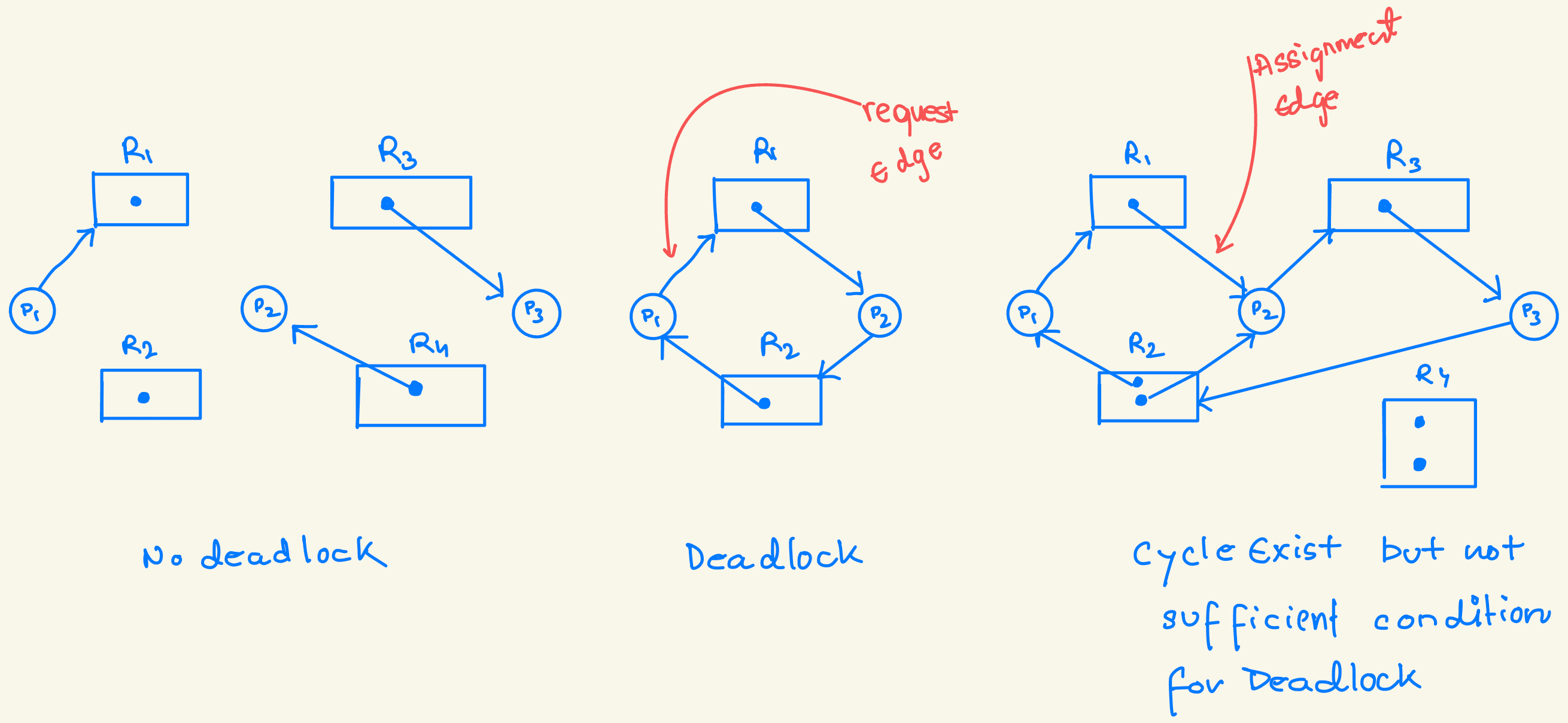
In a deadlock, processes never execute, and system resources are tied up, preventing other jobs from starting. A deadlock situation can arise if the following four conditions hold simultaneously in a system:
-
Mutual Exclusion: At least one resource must be held in a non-shareable mode, meaning only one process can use the resource at a time. If another process requests that resource, it must wait until the resource is released.
-
Hold and Wait: A process must hold at least one resource and simultaneously wait to acquire additional resources currently held by other processes.
-
No Preemption: Resources cannot be forcibly taken from a process. A resource can only be released voluntarily by the process holding it once it has completed its task.
-
Circular Wait: There must be a circular chain of processes {P0, P1, ..., Pn} where P0 is waiting for a resource held by P1, P1 is waiting for a resource held by P2, and so on, with Pn waiting for a resource held by P0.
All four conditions must be present for a deadlock to occur. The circular-wait condition implies the hold-and-wait condition, so these conditions are interconnected.
We can deal with the deadlock problem in one of three ways:
-
We can use a protocol to prevent or avoid deadlocks, ensuring the system will never enter a deadlocked state.
-
We can allow the system to enter a deadlocked state, detect it, and recover it.
-
We can ignore the problem and pretend that deadlocks never occur in the system.
Deadlock prevention
It provides methods to ensure that at least one of the above mentioned criteria cannot hold. These methods prevent deadlocks by constraining how requests for resources can be made.
Mutual Exclusion
-
Non-Sharable Resources
-
At least one resource must be non-sharable.
-
Examples: Mutex locks, which cannot be shared by multiple processes simultaneously.
-
-
Sharable Resources
-
Resources like read-only files allow simultaneous access.
-
Sharable resources cannot cause deadlocks since processes do not need to wait for them.
-
-
Limitation
-
Simply denying mutual exclusion cannot prevent deadlocks.
-
Some resources are inherently non-sharable, such as mutex locks, which require mutual exclusion by design.
-
Hold and Wait
A process must request all its resources before execution or when it holds none to avoid hold and wait.
Protocol I
-
A process requests and holds all needed resources from the start.
-
Example: A process needing a DVD drive, disk file, and printer would hold the printer for its entire execution, even if needed only at the end.
-
Drawback: Inefficient resource utilization.
Protocol II
-
A process requests resources incrementally.
-
Requires releasing all currently held resources before requesting more.
-
Example: Copying data from a DVD to a disk file:
-
Initially requests the DVD drive and disk file.
-
Releases them before requesting the disk file and printer to print the results.
-
Drawback: Inefficient resource utilization and potential starvation.
Common Drawbacks
-
Low resource utilization: Resources may be held but unused for long periods.
-
Potential starvation: A process needing several popular resources might wait indefinitely because one or more resources are constantly in use by other processes.
No Preemption
The no preemption condition for deadlocks means that resources already allocated cannot be forcibly taken away. To counter this, we can implement a protocol to release and reallocate resources.
-
Protocol Implementation:
-
If a process holding resources requests another resource that is not immediately available:
-
Release all currently held resources.
-
Add these resources to the list the process is waiting for.
-
Restart the process only when it can acquire both its old and new requested resources.
-
-
When a process requests resources:
-
Check for Availability:
-
If available, allocate the resources.
-
If not, check if the resources are held by another process also waiting for additional resources.
-
If yes, preempt the needed resources from that waiting process and allocate them to the requesting process.
-
If no, the requesting process must wait.
-
During the wait, its resources might be preempted if requested by another process.
-
-
Restart the process only when it can secure both new and preempted resources.
-
-
-
Applicability:
-
Suitable for resources whose states can be saved and restored, such as CPU registers and memory space.
-
Generally not feasible for mutex locks and semaphores.
-
-
Circular Wait
The circular-wait condition for deadlocks can be prevented by imposing a total ordering on resource types and requiring processes to request resources in increasing order.
Resource Ordering:
-
Let R={R1,R2,...,Rm} be the set of resource types.
-
Assign each resource type a unique integer.
-
Example: Tape drives (1), disk drives (5), printers (12).
-
Request Protocol:
-
A process can request resources only in the predefined order.
-
Example: A process must request a tape drive (1) before requesting a printer (12).
-
This protocol ensures that the circular wait condition cannot hold.
Deadlock avoidance
It requires that the operating system be given additional information in advance concerning which resources a process will request and use during its lifetime. With this extra knowledge, the operating system can decide whether the process should wait for each request.
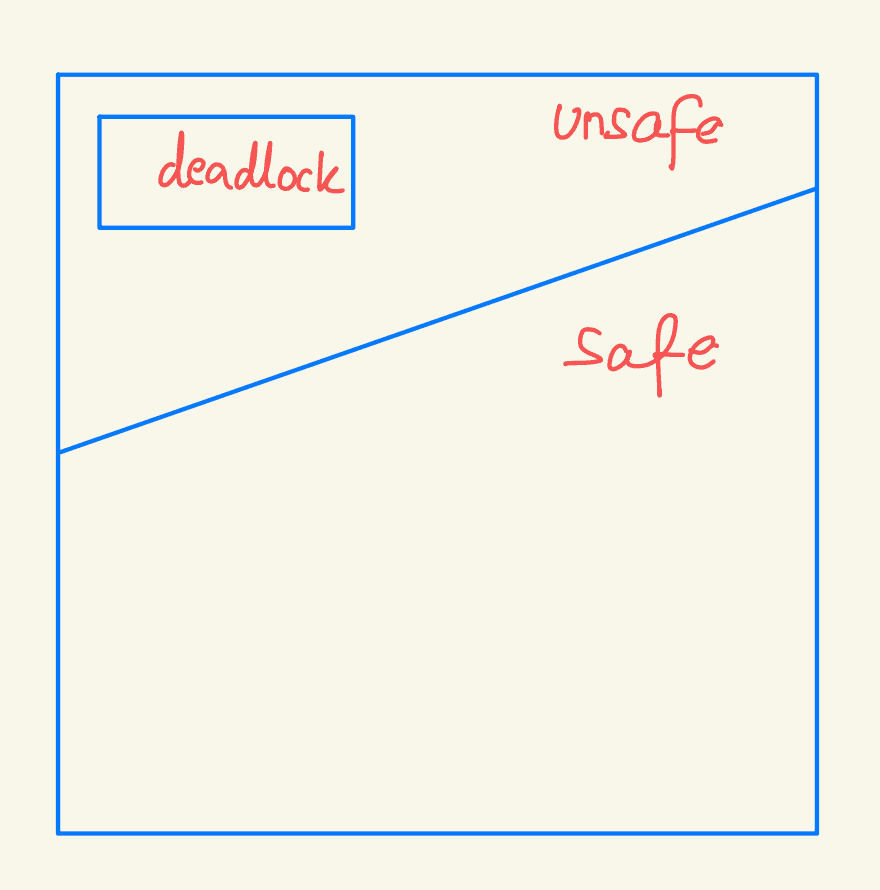
Safe State
A state is safe if the system can allocate resources to each process to its maximum needs in some order without leading to a deadlock. A system is in a safe state if a safe sequence of processes exists where each process's future resource requests can be satisfied by the currently available resources plus those released by previously completed processes. If no such sequence exists, the state is unsafe.
A safe state is not a deadlocked state, but a deadlocked state is always unsafe. However, not all unsafe states result in deadlocks, though they might lead to one. The system should always remain in a safe state to avoid deadlocks.
Resource-Allocation-Graph Algorithm
Used for resource-allocation systems with only one instance of each resource type.
-
Claim Edge:
-
Introduced as a new type of edge.
-
Indicates a future resource request by a process.
-
Represented by a dashed line.
-
-
Edge Conversions:
-
Claim Edge to Request Edge: When a process requests a resource.
-
Request Edge to Assignment Edge: When the resource is allocated.
-
Assignment Edge to Claim Edge: When the resource is released.
-
-
Resource Claiming:
-
All claim edges must be defined before a process starts.
-
Alternatively, claim edges can be added dynamically if all edges for the process are claim edges.
-
-
Cycle Detection:
-
Before granting a resource request, check if converting the claim edge to a request edge forms a cycle.
-
Use a cycle-detection algorithm to ensure safety.
-
-
Granting Requests:
-
If no cycle is detected, allocate the resource.
-
If a cycle is detected, the process must wait.
-
-
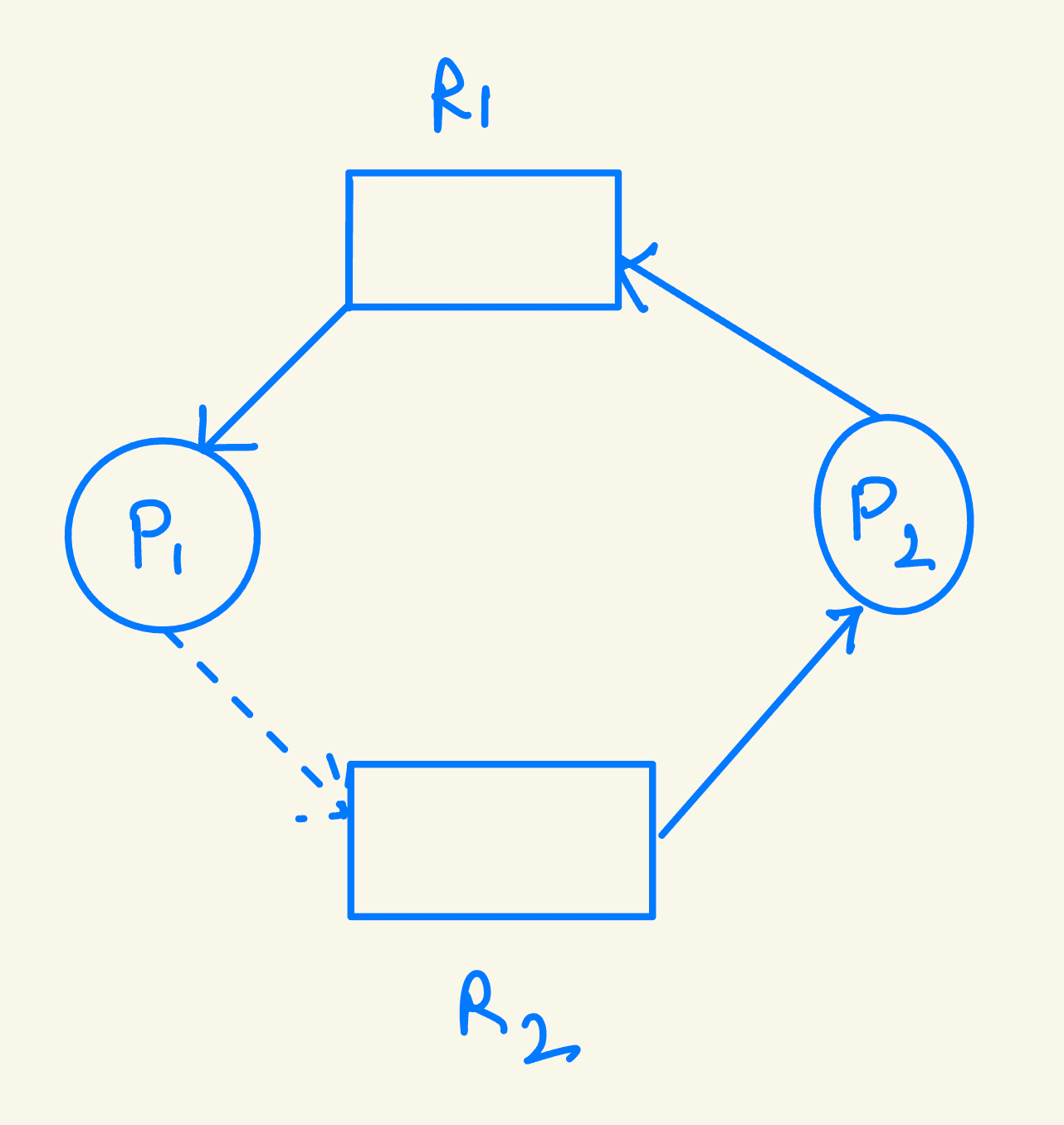
Example Scenario:
-
Consider processes P1 and P2.
-
If P2 requests resource R2 and a cycle forms, the allocation would make the system unsafe.
-
P2's request must wait to see if it will create a cycle with P1 requesting R2 and P2 requesting R1 to avoid deadlock.
-
Banker's Algorithm
The algorithm ensures that the system does not allocate resources in a way that could lead to a deadlock. It is named because it can ensure that a bank can satisfy all its customers' maximum demands.
-
Process Requirements
-
A new process must declare the maximum number of instances it may need.
-
This maximum cannot exceed the total number of resources in the system.
-
-
Resource Allocation
-
When a process requests resources, the system checks if the allocation will keep the system in a safe state.
-
If it will, the resources are allocated; otherwise, the process must wait.
-
-
Data Structures
-
Available: A vector indicating the number of available resources of each type.
-
Max: An n×m matrix showing the maximum demand of each process.
-
Allocation: An n×m matrix showing the resources currently allocated to each process.
-
Need: An n×m matrix showing the remaining resource needs of each process.
-
-
Safety Algorithm
-
Initialize vectors Work (equal to Available) and Finish (all false).
-
Find an index i such that Finish[i] == false and Need[i] <= Work.
-
If found, update Work = Work + Allocation[i] and Finish[i] = true, then repeat step 2.
-
If Finish[i] is true for all i, the system is in a safe state.
-
-
Resource-Request Algorithm
-
Check if Request[i] <= Need[i]. If not, raise an error.
-
Check if Request[i] <= Available. If not, the process must wait.
-
Temporarily allocate the requested resources to the process and check if the system remains in a safe state:
-
Update Available = Available - Request[i]
-
Update Allocation[i] = Allocation[i] + Request[i]
-
Update Need[i] = Need[i] - Request[i]
-
If the new state is safe, allocate resources. If not, revert to the old state, and the process must wait.
-
-
Deadlock Detection
It comprises algorithms examining the system's state and determining if a deadlock has occurred.
-
Detection and recovery require maintaining the necessary information and executing detection algorithms.
-
Potential costs are associated with recovering from deadlocks, including possible system losses.
Systems with a single instance of each resource type
-
Use a deadlock-detection algorithm based on a wait-for graph.
-
Derived from the resource-allocation graph by removing resource nodes and collapsing edges.
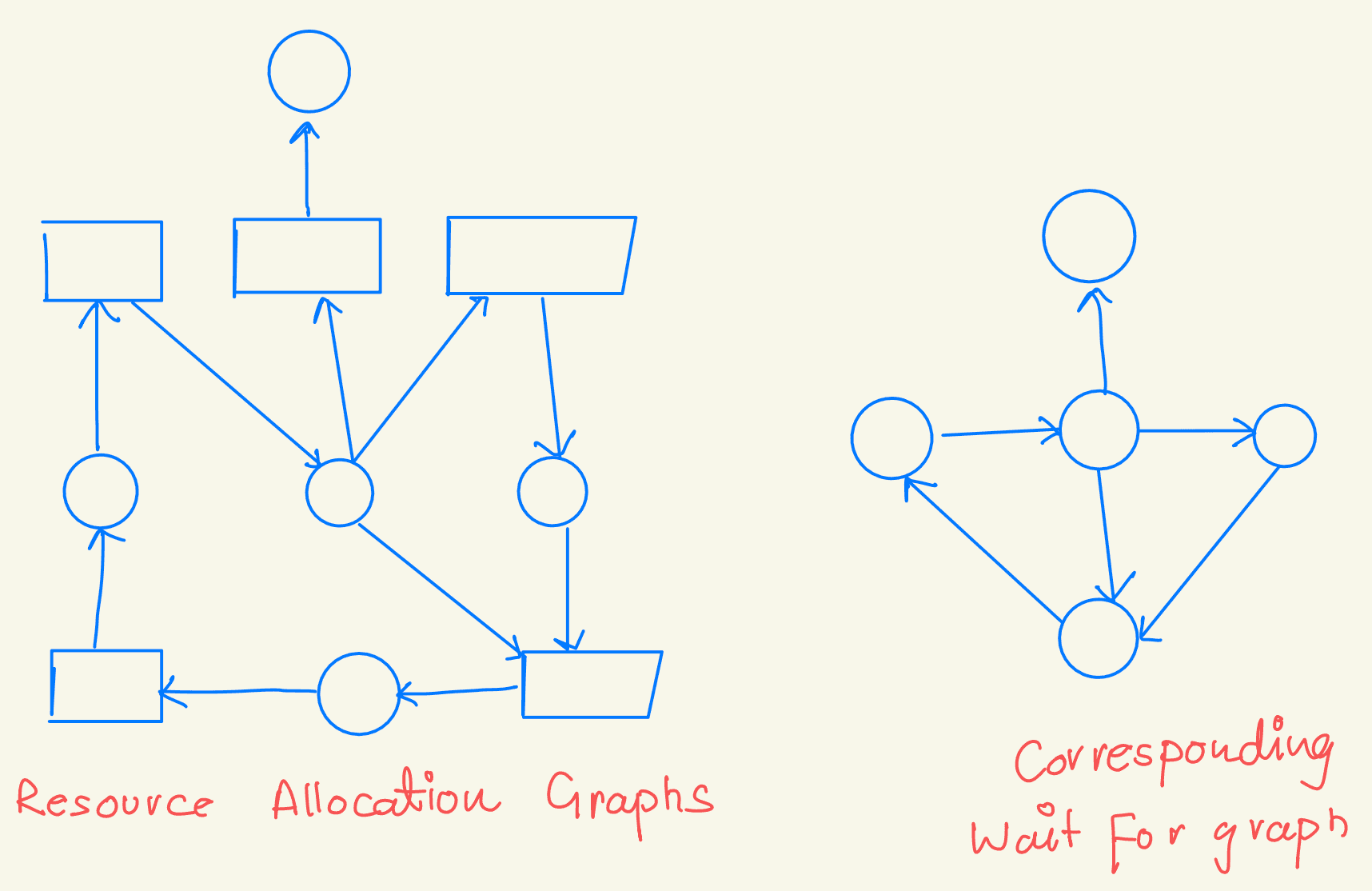
Wait-For Graph
-
An edge from Pi to Pj indicates that process Pi is waiting for Pj to release a needed resource.
-
An edge Pi→Pj exists if the resource-allocation graph has edges Pi→Rq and Rq→Pj for some resource Rq.
A deadlock is present if the wait-for graph contains a cycle. The system must maintain the wait-for graph and periodically run an algorithm to detect cycles. Detecting a cycle in a graph requires O(n^2) operations, where n is the number of vertices.
Using a wait-for graph, systems can efficiently detect deadlocks in environments where each resource has only a single instance. The periodic cycle detection helps identify and address deadlocks on time.
Systems with multiple instances of each resource type
The wait-for-graph scheme is unsuitable for systems with multiple instances of each resource type. Hence, we use a deadlock-detection algorithm similar to the Banker's Algorithm.
-
Data Structures
-
Available: Vector indicating the number of available resources of each type.
-
Allocation: n×m matrix showing the resources currently allocated to each process.
-
Request: n×m matrix indicating the current request of each process.
-
-
Detection Algorithm
-
Initialize vectors Work (equal to Available) and Finish (true if Allocation[i] is 0, else false).
-
Find an index i such that:
-
Finish[i] == false
-
Request[i] <= Work
-
-
If such an i exists:
-
Update Work = Work + Allocation[i]
-
Set Finish[i] = true
-
-
Repeat step 2.
-
If no such i exists, check Finish:
-
If any Finish[i] == false, the system is in a deadlocked state, and P_i is part of the deadlock.
-
-
Algorithm Complexity: Requires O(m×n^2)operations to detect a deadlock.
-
Optimistic Assumption
-
if Request[i] <= Work, process P_i will complete and return its resources.
-
If incorrect, the deadlock will be detected in the next algorithm invocation.
-
When to Invoke the Deadlock Detection Algorithm?
-
Likelihood of deadlock occurrence.
-
Number of processes affected by deadlock.
-
Frequent Deadlocks:
-
Invoke the detection algorithm frequently if deadlocks are common.
-
Idle resources in deadlocked processes until the deadlock is resolved.
-
The number of processes in the deadlock cycle may increase over time.
-
-
Triggering Condition:
-
Deadlocks occur when a process makes a request that cannot be immediately granted.
-
This request might complete a chain of waiting processes, causing a deadlock.
-
In extreme cases, run the detection algorithm whenever a request cannot be immediately granted.
-
This approach identifies the deadlocked set and the process that "caused" the deadlock (though all involved processes contribute to the cycle).
-
-
Performance Considerations:
-
Running the detection algorithm for every request incurs high computation overhead.
-
A more efficient approach is to invoke the algorithm at set intervals, such as:
-
Once per hour.
-
Whenever CPU utilization drops below 40%.
-
Regular interval checks may reveal many cycles in the resource graph, making it hard to identify the specific process that caused the deadlock.
-
Recovery from Deadlock
When a detection algorithm identifies a deadlock, there are several recovery options:
-
Process Termination:
-
Abort all deadlocked processes: This breaks the deadlock cycle but is costly since partial computations are lost and must be redone.
-
Abort one process at a time: Abort processes one by one and rerun the detection algorithm each time until the deadlock is resolved. This method is time-consuming and incurs overhead.
-
Challenges: Terminating a process can leave resources in an incorrect state (e.g., a half-updated file or an interrupted print job).
-
Choosing a Process to Abort:
-
Prioritize processes to minimize cost.
-
Consider factors such as:
-
Process priority.
-
Computation time so far and estimated completion time.
-
Number and type of resources used.
-
Remaining resource needs.
-
Number of processes to terminate.
-
Process type (interactive or batch).
-
-
-
-
Resource Preemption:
-
Preempt resources from deadlocked processes and allocate them to others until the cycle is broken.
-
Issues to Address:
-
Selecting a Victim:
- Determine which resources and processes to preempt based on cost factors.
-
Rollback:
-
Rollback processes to a safe state and restart them.
-
The simplest solution is a total rollback (abort and restart the process).
-
-
Starvation:
-
Ensure that the same process is not repeatedly chosen as a victim.
-
Include the number of rollbacks in the cost factor to prevent indefinite delays for any single process.
-
-
In conclusion, understanding and managing process synchronization and deadlocks are crucial for maintaining system efficiency and preventing resource contention. By implementing strategies for mutual exclusion, hold and wait, no preemption, and circular wait, operating systems can effectively prevent or resolve deadlock situations, ensuring smooth and reliable operation.
Some things to keep in mind:
-
Mutual Exclusion: Ensures that only one process or thread can execute a critical code section.
-
Critical-Section Problem: Solved using algorithms that assume only storage interlock is available.
-
Semaphores: Overcome busy waiting and solve various synchronization problems especially with hardware support for atomic operations.
-
Transactions: Must be executed atomically either fully completed or not at all.
-
Write-Ahead Log: Ensures atomicity despite system failure by recording updates on stable storage.
-
Recovery: Uses the log to restore the state of data items via undo and redo operations.
-
Checkpoints: Reduce overhead in searching the log after system failures.
-
Deadlock State: It occurs when two or more processes wait indefinitely for an event caused only by one of the waiting processes.
-
Mutual Exclusion: At least one resource must be held in a non-sharable mode.
-
Hold and Wait: A process holding at least one resource waits to acquire additional resources held by other processes.
-
No Preemption: Resources cannot be forcibly taken from processes holding them.
-
Circular Wait: A closed chain of processes exists, where each process holds at least one resource needed by the following process in the chain.
-
That's a wrap! See you in the next issue. Have a great start to the week :)
Comments