
Threads and Processes
Hello Readers,
We have unpacked the Operating system's design and gone through the process of booting up a system.
How exactly is a task being executed, and how is a calculation or an interface working?
We will understand the notion of a process, describe the features, and look at different communication options. We will discuss Parallelism and Concurrency and the challenges of multi-core programming. We will go further to understand threads and look at the library implementations.
Let's dive in.
A program is a set of instructions.
Processes
With continuously evolving computer systems, we need firm control and more compartmentalization of various programs; that is how we got the term process. A Process is a unit of work in a modern time-sharing system.
A process is a program in execution and has the following structure:
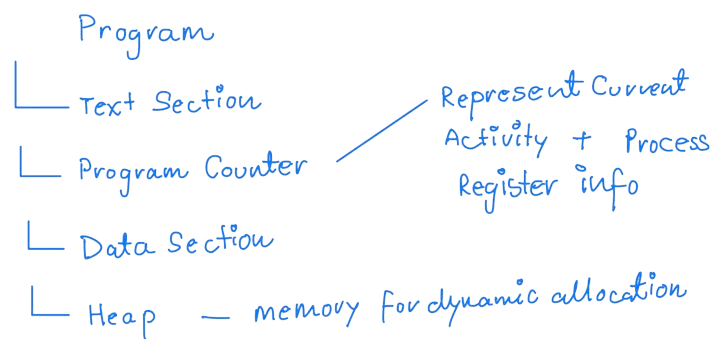
A process is a collection of program code and the current activity of the program.
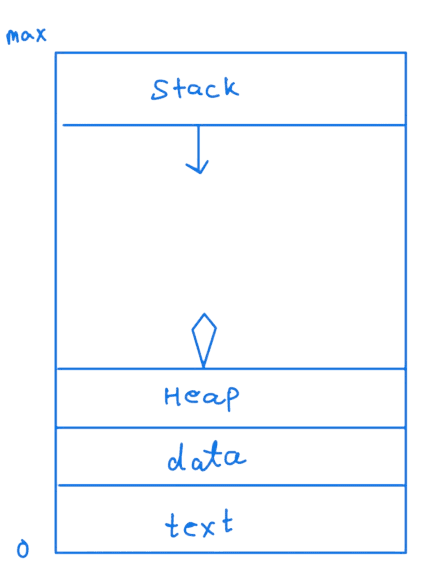
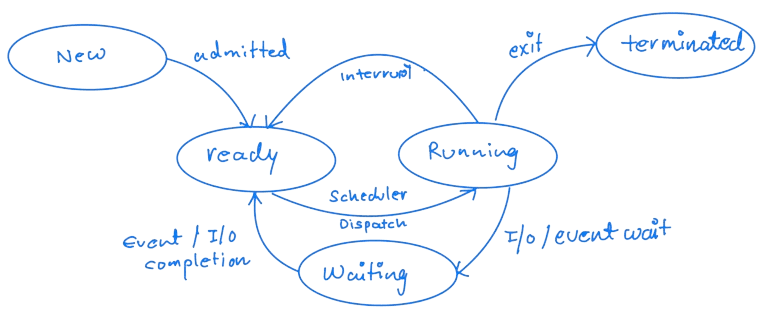
As a program is executed with a process, there are changes in the state of the process defined in the current activity.
Process State
Each process is represented by a Process control block(PCB). PCB acts as a repository of information that varies from process to process.
Process Control Block
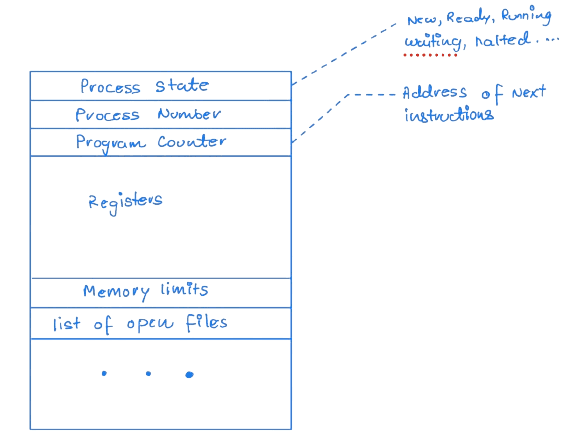
The state information is saved when an interrupt occurs to continue the process correctly.
Process Scheduling
Now, One can wonder how the processes are scheduled and executed.
All processes that enter the system are put into a job queue, and the processes in the main memory and ready to execute are kept in the queue.
For example, the state of a process is represented by the field-long state in this structure. Within the Linux kernel, all active processes are defined using a doubly linked list of task struct. The kernel maintains a pointer — current — for the process currently being executed on the system, as shown below.
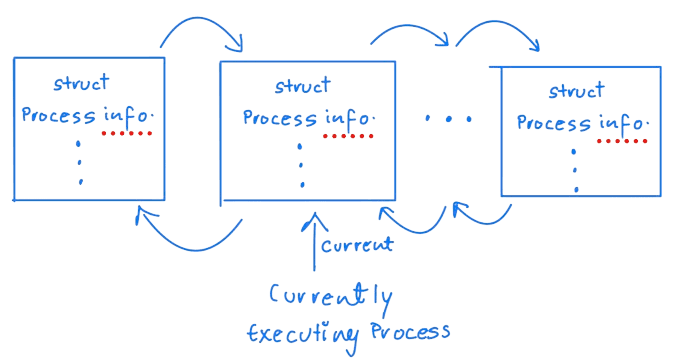
Scheduler
Since the process moves between different scheduling queues, it is the job of a scheduler to carry out the selection process.
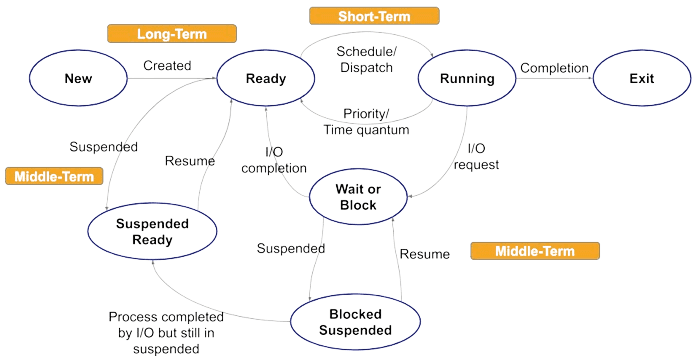
Context Switch
As we have observed, Interrupt causes a change in the process. Switching the CPU to another process requires performing a state save of the current process and a state restore of a different process. This task is known as a context switch.
Process Creation
During execution, a process may create several new processes via a create-process system call. The creating process is called a parent process, and the new processes are called the children of that process. These new processes may create other processes, forming a tree of processes.
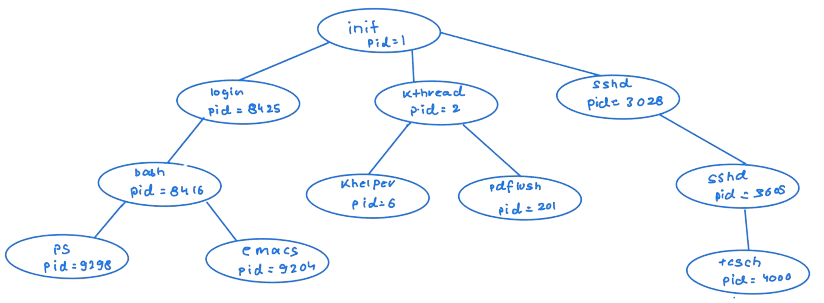
A unique process identifier (or PID), typically an integer number, identifies a process.

Process Termination
A process terminates when it finishes executing its final statement and asks the operating system to delete it using the exit() system call. At that point, the process may return a status value (typically an integer) to its parent process (via the wait() system call). The operating system deallocates all the process resources—including physical and virtual memory, open files, and I/O buffers.
A process that has been terminated but whose parent has not yet called wait() is known as a zombie process. If a parent did not invoke wait() and instead terminated, leaving its child as an orphan.
Inter Process Communication(IPC)
The cooperating processes require IPC, and there are two fundamental models.
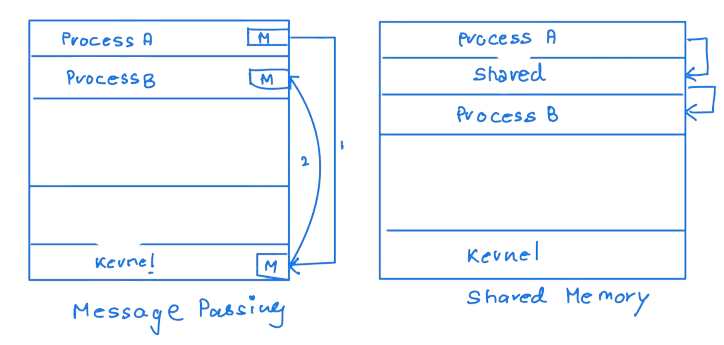
In Shared memory communication, these are the requirements
- A region of shared memory
- A process should attach itself to the process's address space, which has a shared memory segment.
Message passing provides a communication link to synchronize the actions without sharing the same address space. For example, communication in a distributed environment uses message passing where the communicating processes reside on different computers connected by a network.
The mechanism provides at least two operations: send(message) and receive(messages) in different ways.
Direct Communication
A communication link in the direct communication scheme has the following properties:
- A link is established automatically between every pair of processes that want to communicate. The processes need to know each other's identity in order to communicate.
- A link is associated with precisely two processes.
- Between each pair of processes, precisely one link exists.
The disadvantage of direct communication is the limited modularity of the resulting process definitions. Changing the identifier of a process may necessitate examining all other process definitions.
Indirect Communication
The messages are sent to and received from mailboxes or ports.
- A mailbox can be viewed abstractly as an object into which messages can be placed by processes and from which messages can be removed.
- Each mailbox has a unique identification.
In this scheme, a communication link has the following properties:
- A link is established between a pair of processes only if both members have a shared mailbox.
- A link may be associated with more than two processes.
- Between each pair of communicating processes, several different links may exist, with each link corresponding to one mailbox.
Synchronous and Asynchronous Communication
Message passing may be either blocking or nonblocking — also known as synchronous and asynchronous.
- Blocking send: The sending process stops until the receiving process or the mailbox receives the message.
- Nonblocking send: The sending process sends the message and resumes operation.
- Blocking receive: The receiver blocks until a message is available.
- Nonblocking receiver: The receiver retrieves either a valid message or a null.
Communication in Client Server Systems
Message passing and Shared Memory can be used for communication in client-server systems. Let's have a look.
Sockets
Sockets are a tuple of IP address and port information. The socket is an endpoint of communication used by the processes to communicate over a network. The IP address 127.0.0.1 is known as loopback because it refers to itself.
Sockets are low-level forms of communication between distributed processes and always allow an unstructured data stream.
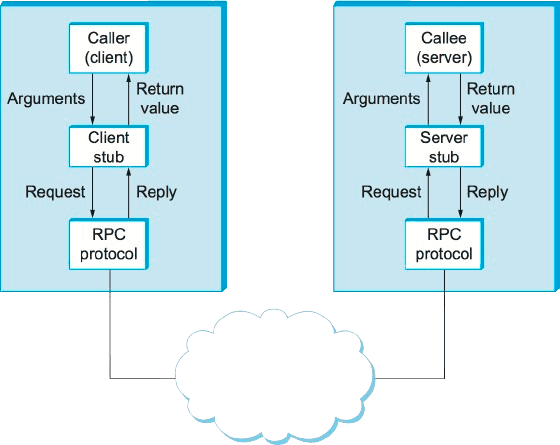
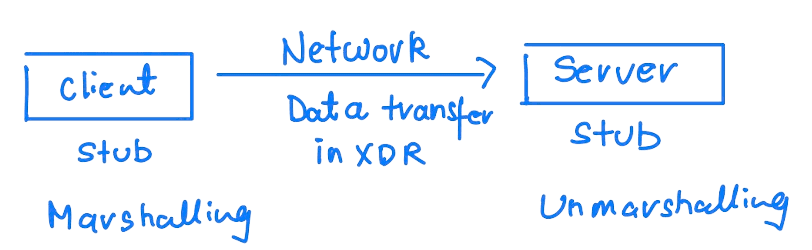
Remote Procedural Calls
The processes are executed on different systems; a message-based communication scheme is required for remote service.

Messages go to the RPC daemon, and the remote system listens to the port. The message is well structured and consists of Process identifier, arguments and the address of the RPC daemon. RPC provides abstraction, which makes it look like communication is happening on a local machine.
Consider the representation of 32-bit integers. Some systems (big-endian) store the most significant byte first, while others (little-endian) store the least significant byte first.
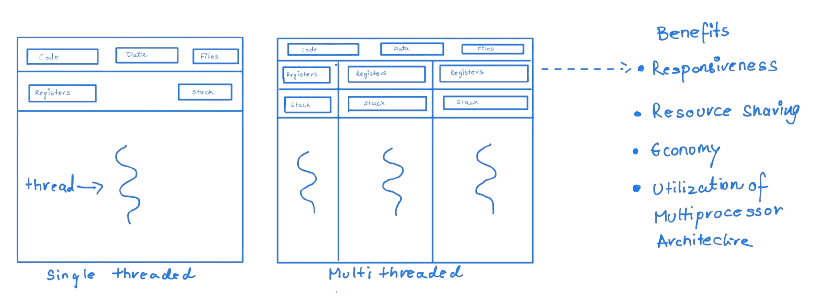
So far, we have assumed the process is the program's execution with a single control thread. A process can also contain multiple threads of control.
Threads
Before diving into the threads, let's understand parallelism and concurrency and why there is a need to distinguish between them.
Multi-threaded programming provides a mechanism for efficient use of a system's multiple computing cores, resulting in concurrency.
For example, Consider an application with four threads.
On a system with a single computing core:
Concurrency means that the execution of the threads will be interleaved over time because the processing core can execute only one thread at a time.
On a system with multiple cores:
Concurrency lets threads run in parallel since the system can assign a separate thread to each core.
A Parallel system can perform more than one task simultaneously. In most instances, applications use a hybrid of these two strategies. Data parallelism focuses on distributing subsets of the same data across multiple computing cores and performing the same operation on each core. Task parallelism involves distributing not data but tasks (threads) across multiple computing cores. A concurrent system supports more than one task by allowing all the tasks to make progress. Thus, it is possible to have concurrency without parallelism.
Multithreading Model
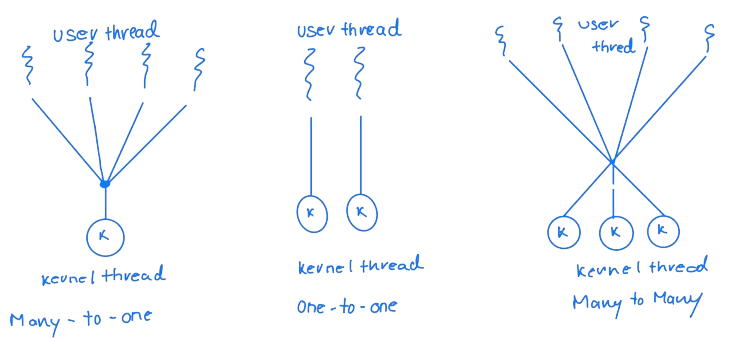
A thread library called POSIX Pthreads provides an API for creating and managing threads. This thread library can be used as a user or kernel-level library. Pthreads refers to the POSIX standard specification for thread behaviour (IEEE 1003.1c), defining an API for thread creation and synchronization.
Major Challenges with Threading
The fork() and exec() System call
- fork(): The behaviour of the fork() system call, used to create a duplicate process, varies in multi-threaded programs.
- Some UNIX systems offer two fork() variants: one duplicates all threads, and the other only quotes the calling thread.
- exec(): Typically retains its conventional function; invoking exec() in a thread replaces the entire process, including all threads, with a new program.
- Choosing fork() Version:
- If exec() follows fork() immediately, duplicating all threads is redundant since exec() will replace the entire process. In such cases, copying only the calling thread is sufficient.
- Without an exec() call post-fork, duplicating all threads in the new process is advisable to maintain the program's multi-threaded nature.
Thread Cancellation
Thread Cancellation halts an active thread during its execution and is often used in multi-threaded programs to manage tasks efficiently. For instance, in a program scanning a database with multiple threads, threads may be cancelled once one thread retrieves the needed data.
- Cancellation Methods:
- Asynchronous Cancellation: Involves one thread instantly terminating the target thread without regard for its current state or resource ownership.
- Deferred Cancellation: The target thread periodically self-checks and decides to cancel itself, ensuring a voluntary termination process voluntarily.
- Resource Management: Managing resources assigned to a thread that gets cancelled poses challenges, especially when the thread is terminated while updating shared information.
- Cancellation Points: Specific points within a thread's execution where it can safely check for cancellation requests and terminate if needed, ensuring resource handling and coordination with other threads are maintained.
Thread Pool
Each time a user accesses a page, the server initiates an independent thread, potentially leading to resource exhaustion if there's no limit on active threads. Creating a new thread should consume less time than the thread spends handling a request to save CPU resources.
A thread pool concept is introduced where a predetermined number of threads are created at the start and reused for multiple requests.
- Thread Pool Mechanics: Threads from this pool are deployed to handle incoming requests and return to the pool after completing their tasks, ready for new assignments.
- Resource Efficiency: This approach ensures resource efficiency, especially on systems with limited support for concurrent threads, by reusing threads instead of creating new ones for each request.
Operating system example: Linux Threads
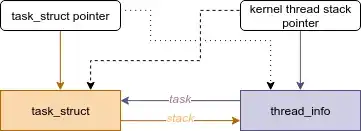
Task Representation in Linux: Each task in the Linux kernel is represented by a unique data structure (struct task_struct), which contains pointers to other structures holding task-specific data like open files, signals, and virtual memory.
System Calls
- fork(): Creates a new task by duplicating the parent process's data structures.
- clone(): It also creates a new task but can share the parent's data structures based on specified flags, allowing for varying levels of sharing between functions.
- Linux uses the term task —rather than process or thread— when referring to a flow of control within a program.
- When clone() is invoked, a set of flags is passed that determine how much sharing will occur between the parent and child tasks.
The topics discussed provide insights into the nature, attributes, and functionalities of processes and threads, along with the challenges threading presents. It also provides a clear distinction between concurrency and parallelism.
Some things to keep in mind:
Processes
- The operating system manages processes through long-term (job) and short-term (CPU) scheduling, determining which processes enter the ready queue and which one from the ready queue gets the CPU time.
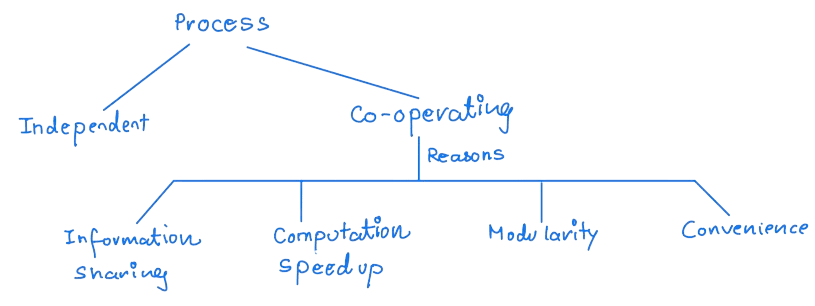
- Operating systems enable parent processes to create child processes, which can execute concurrently for various reasons such as information sharing, computation speedup, modularity, and convenience.
Threads
- Multithreading enhances responsiveness, allows resource sharing, and improves efficiency, particularly on multi-core systems.
- Library-like POSIX Pthreads provide APIs for thread management, while implicit threading allows compilers and libraries to manage threads automatically.
Concurrency vs. Parallelism
- Concurrency: Involves multiple threads making progress within a single core by interleaving their execution, allowing efficient use of CPU time and responsiveness.
- Parallelism: Utilizes multiple cores to execute different threads or processes simultaneously, leading to faster completion of tasks.
That's a wrap! See you in the next issue. Have a great start to the week :)
Comments