
CPU Scheduling: Principles and Challenges
Hello readers 👋,
We have reviewed the operating system design and understood the threads and processes in previous issues.
How exactly a CPU is handling the threads and processes and how do the processes make sure that they are working in synchronization?

We will understand the components of CPU scheduling and focus on multi-processor scheduling in Distributed systems.
Let's dive in!
We know the process is the program's execution with a single or multiple control threads. The end goal is to utilize the CPU efficiently and optimally to increase responsiveness and utilize the multi-processor architecture. CPU scheduling forms the base of multi-programming operating systems. The operating system helps to increase productivity by switching among the CPU processes.
Why do we require CPU Scheduling?
The idea is logical. A process is executed until it typically waits for some I/O request, meaning the CPU sits idle. With multi-programming, we aim to use the time productively. Several processes are kept in memory at one time. When one process has to wait, the operating system assigns the CPU to another process to use that wait time. This pattern continues. Scheduling is a fundamental operating system function; almost all computer resources are scheduled before use.
CPU Scheduling is central to operating system design since the CPU is the primary computer resource.
CPU I/O Burst Cycle
Process execution consists of a cycle of CPU execution and I/O wait. Processes move between these two states.
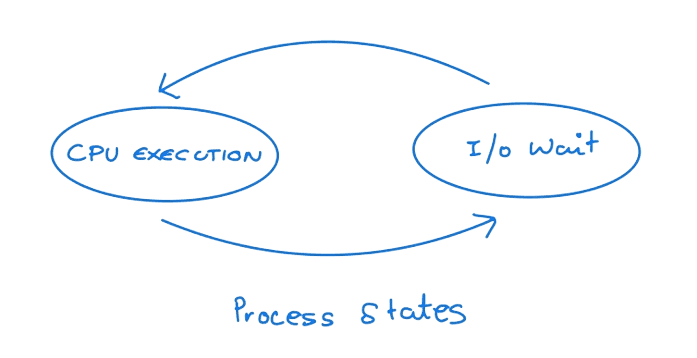
An I/O-bound program typically has many short CPU bursts, and A CPU-bound program might have a few long CPU bursts. The distribution is vital at the time of selection of CPU scheduling algorithms.
CPU Scheduler
When the CPU becomes idle, the process selection is made by a short-term scheduler (or CPU scheduler). The scheduler selects from those ready to execute and allocates the CPU to that process.
The CPU scheduling takes place in these process state change situations.
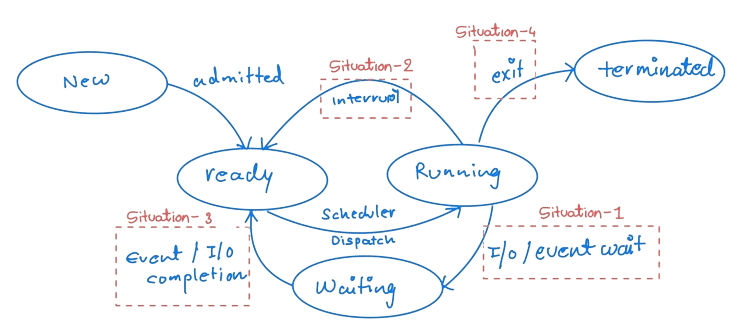
In Situations 1 and 4, the scheduling scheme is non-preemptive or cooperative. Otherwise, it is preemptive.
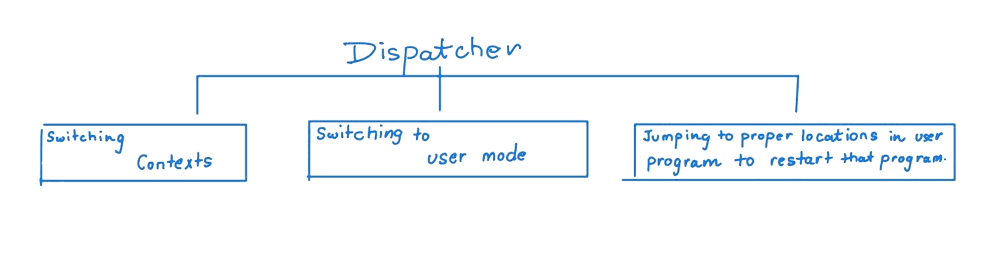
Dispatcher
The dispatcher is the module that gives control of the CPU to the process selected by the short-term scheduler.
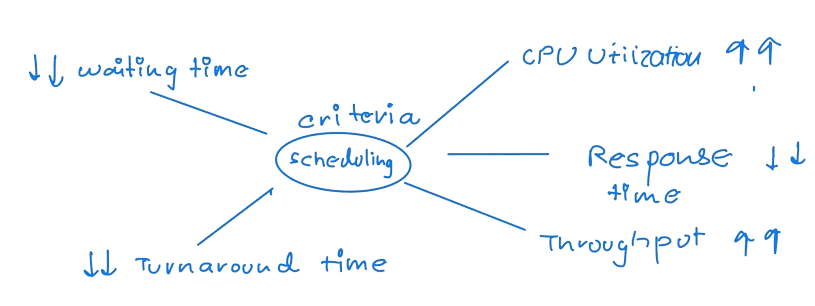
Scheduling Criteria
Different CPU-scheduling algorithms have different properties, and choosing a particular algorithm may favour one class of processes. In deciding which algorithm to use for a specific situation, we must consider the properties of the various algorithms.
These are the metrics to decide for the algorithm.
-
CPU utilization. We want to keep the CPU as busy as possible. Conceptually, CPU utilization can range from 0 to 100 per cent. A real system should range from 40 per cent (for a lightly loaded system) to 90 per cent (for a heavily loaded system).
-
Throughput. If the CPU is busy executing processes, then work is being done. One measure of work is the number of processes completed per time unit, which is called throughput. For long processes, this rate may be one process per hour; for short transactions, it may be ten processes per second.
-
Turnaround time. From the point of view of a particular process, the critical criterion is how long it takes to execute that process. The turnaround time is the time of submission of a process to the time of completion. Turnaround time is the sum of the periods spent waiting to get into memory, waiting in the ready queue, executing on the CPU, and doing I/O.
-
Waiting time. The CPU-scheduling algorithm does not affect the time a process executes or does I/O. It affects only the time a process spends waiting in the ready queue. Waiting time is the sum of the periods spent waiting in the ready queue.
-
Response time. In an interactive system, turnaround time may not be the best criterion. Often, a process can produce some output relatively early and continue computing new results while previous results are output to the user. Thus, another measure is the time from submitting a request until the first response is produced. This measure, called response time, is the time it takes to start responding, not the time it takes to output the response. The speed of the output device generally limits the turnaround time.
Scheduling Algorithms
Many CPU process scheduling algorithms exist, and I will list a few of them. Detailed explanations of these algorithms are widely available online.
- First-Come, First-Served Scheduling
- Shortest-Job-First Scheduling
- Priority Scheduling
- Round-Robin Scheduling
- Multilevel Queue Scheduling
- Multilevel Feedback Queue Scheduling
The previous issue introduced threads to the process model, distinguishing between user-level and kernel-level threads. The operating system schedules kernel-level threads, while a thread library manages user-level threads and is invisible to the kernel. User-level threads must map to a kernel-level thread or a lightweight process (LWP) to run on a CPU.
User Level Threads
- The thread library handles user-level threads in a process.
- They utilize process-contention scope (PCS) for scheduling, competing for CPU time with other threads in the same process.
- Priority-Based Scheduling: Threads are typically scheduled based on their priority, which is set by the programmer and not altered by the thread lbrary, although some libraries allow for changing thread priorities.
- Higher priority threads preempt lower priority ones, but equal priority threads do not necessarily have time slicing.
Kernel Level Threads
- Kernel threads are scheduled directly by the operating system.
- They utilize system-contention scope (SCS) for scheduling, involves competition among all threads in the system, regardless of which process they blong to.
- Windows, Linux, and Solaris use this model, mapping each user-level thread to a kernel thread.
Example: PThread Scheduling
POSIX Pthread API set up the contention scopes during thread creation by the following process:
Contention Scope Values
PTHREAD_SCOPE_PROCESS: Uses PCS scheduling.PTHREAD_SCOPE_SYSTEM: Uses SCS scheduling.
Scheduling Policies
PTHREAD_SCOPE_PROCESS: On systems with a many-to-many model, schedules user-level threads on available LWPs, managed by the thread library.PTHREAD_SCOPE_SYSTEM: Schedules each user-level thread to its own LWP, similar to a one-to-one threading model.
API Functions
pthread_attr_setscope(pthread_attr_t *attr, int scope): Sets the contention scope for thread attributes. Scope can be eitherPTHREAD_SCOPE_SYSTEMorPTHREAD_SCOPE_PROCESS.pthread_attr_getscope(pthread_attr_t *attr, int *scope): Retrieves the current contention scope setting from the thread attributes.
Multi-Processor Scheduling
Load sharing becomes possible when considering multi-processor CPUs, but scheduling problems become more complex.
-
Asymmetric multiprocessing: It involves designating a single processor as the primary server. This processor makes all scheduling decisions, handles I/O processing, and manages other system activities.
-
Symmetric multiprocessing (SMP): Scheduling where each processor independently schedules tasks. Processors may either share a common ready queue or maintain individual private queues. In either case, the scheduler for each processor assesses the ready queue to select a process for execution. Most modern operating systems utilize SMP, including Windows, Linux, and Mac OS X.
Processor Affinity
Consider what happens to cache memory when a process runs on a specific processor and one process has to migrate to another processor.
Cache Memory Utilization
- When a process runs on a specific processor, it populates its cache with recently accessed data.
- Successive memory accesses by the process are often quickly satisfied that results to enhanced performance from this cache.
Impact of Process Migration
- Migrating a process to another processor necessitates invalidating the cache on the original processor.
- The cache on the new processor must be repopulated, which incurs a significant cost.
Due to the high costs of cache invalidation and re-population, most Symmetric Multiprocessing (SMP) systems favour keeping a process on the same processor, a strategy known as processor affinity. Processor affinity helps maintain cache efficiency by minimizing the need for cache refreshes.
-
Soft Affinity: The operating system attempts to keep a process on the same processor without guaranteeing it. This allows for some flexibility in process scheduling.
-
Hard Affinity: Supported by specific system calls, hard affinity allows a process to specify precisely which processors it can run on, ensuring more stringent control over process placement.
-
Challenges
-
Performance Optimization: Balancing processor affinity with overall system performance and resource utilization is challenging, especially in dynamic, multi-tasking environments.
-
System Complexity: Implementing effective CPU scheduler and memory-placement algorithms that use processor affinity and NUMA architectures increases system complexity.
-
Load Balancing
Balancing the workload among all processors is crucial in Symmetric Multiprocessing (SMP) systems to maximize the utilization of multiple processors. Load balancing is generally required in systems where each processor has its queue of processes waiting for execution. Load balancing is less critical in the common run queue, as idle processors immediately pick up a process from the shared queue.
-
Approaches to Load Balancing
-
Push Migration: This way of load balancing redistributes processes from overloaded processors to less busy or idle ones based on periodic load evaluations.
-
Pull Migration: An idle processor takes on a process from an overloaded processor's queue.
-
Many systems simultaneously implement push and pull migration to optimize processor load distribution.
Load Balancing and Processor Affinity
-
Load balancing sometimes conflicts with processor affinity's benefits since the latter focuses on keeping a process on the same processor to leverage cached data.
-
Moving processes between processors (either by pushing or pulling) negates the caching advantages by requiring data to be reloaded into a new processor's cache.
Systems engineering involves trade-offs between maintaining processor affinity and ensuring efficient load distribution.
Example: Linux Scheduling
There was an introduction of a new scheduling algorithm that operates in constant time complexity O(1), unaffected by the number of tasks in versions after 2.5.
Scheduler: Preemptive and Priority-Based
- Linux scheduler operates preemptively with a dual priority range:
- Real-time range: 0 to 99
- "Nice" Value range: 100 to 140
- Tasks with numerically lower priority values receive higher scheduling priority.
- Contrary to many other systems like Solaris and Windows XP, higher-priority tasks are assigned longer quanta in Linux.
Priority and Time Quantum Relationship
- Higher-priority (lower numerical value) tasks receive up to 200 ms time slices, aiding real-time performance.
- Lower-priority (higher numerical value) tasks receive shorter time slices of around 10 ms, suitable for less critical operations.
Run queue Management
- Each processor in SMP systems has its run queue that can be managed independently.
- Run queues contain two priority arrays:
- Active Array: Holds tasks with the remaining time in their time slices.
- Expired Array: Contains tasks that have exhausted their time slices.
- Tasks are cycled between these arrays to balance the load and manage task prioritization effectively.
Real-time Scheduling Compliance
- Linux supports POSIX.1b real-time scheduling:
- Real-time tasks have static priorities.
- Other tasks have dynamic priorities, adjusted based on their "Nice" values and interactivity (interaction with I/O operations influences priority adjustments).
Dynamic Priority Recalculation
- Occurs when a task moves to the expired array after depleting its time quantum.
- Ensures tasks in the active array are always prioritized according to the latest scheduling needs, facilitating efficient CPU usage.
The topics discussed provide insights into the functionalities of CPU scheduling, along with the challenges. CPU scheduling is essential for managing how processes and threads efficiently access the limited resources of the CPU, ensuring optimal performance and resource utilization.
Some things to keep in mind:
- CPU Scheduler is a system component that allocates CPU time to various running processes based on a specific scheduling algorithm.
- Scheduling metrics include utilization, throughput, turnaround, waiting time, and response time, guiding how scheduling decisions enhance system efficiency.
- Linux uses a priority-based, preemptive scheduling algorithm capable of handling many tasks efficiently with mechanisms to support both system and real-time tasks.
- Maintaining processor affinity and ensuring efficient load distribution are essential in CPU scheduling.
That's a wrap! See you in the next issue. Have a great start to the week :)
Comments