
Fundamentals of Text Retrieval
Large Language Models(LLMs) is a hot topic after the release of GPT-3 and has seen a fast paced adoption across industries.
Text retrieval is a fundamental building block of modern search algorithms and application powered by LLMs.
In this post, we will discuss the classical text retrieval models in detail covering the following topics:
- Extracting a vocabulary of terms by exploring documents and performing simple linguistic processing.
- Splitting the documents into smaller parts to improve retrieval performance.
- Tokenizing the documents to extract meaningful units of text.
- Summarizing the extracted features into a concise representation for efficient retrieval.
Introduction
For example, the search system of our laptop scan through all the data for each query. This is not feasible for large datasets.The search system should be able to retrieve the relevant documents quickly and efficiently. Instead, the search is divided into two steps:
Indexing Phase - The main challenge is creating consice representation of the documents.
Querying Phase - The main challenge is relevance ranking of the documents.
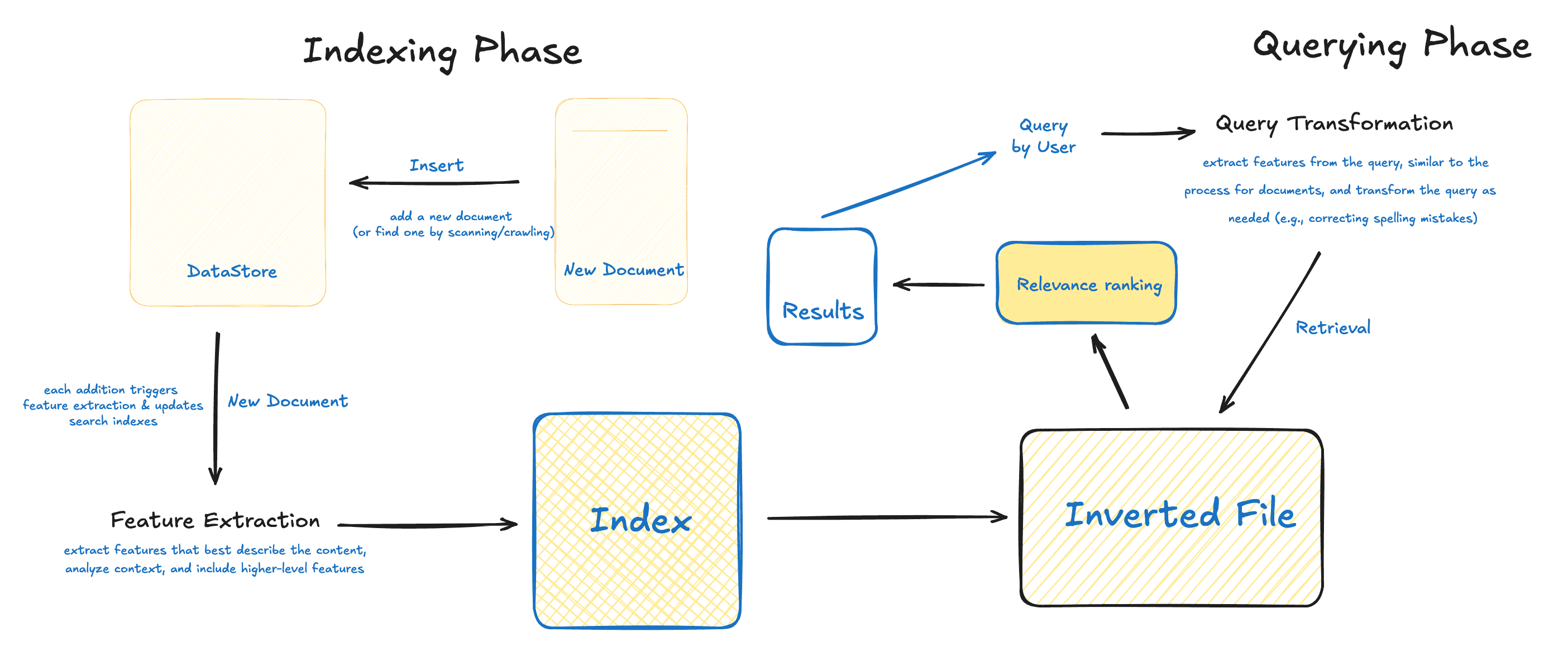
Fundamentals
We will now explore the fundamentals steps of feature extraction from source documents during the indexing phase. There are four main steps of feature extraction, extract, split, tokenize and summarize. The outcomes includes a vocabulary containing all terms found in the documents, a feature representation that can be stored in the index along with the metadata from the source documents. Let's discuss each step in detail.
Step 1: Extract
Text documents are available in different formats like HTML, PDF, EPUB, etc. We consider a simple example in HTML to understand the extraction process.
The first step is:
- Extracting the meta information, like title, author, date, etc.
- Sequence of characters that form the text stream without control sequences like newlines, tabs, etc.
- Formatting information like font size, color, encoding, etc.
Next, we must decide the character encoding of the text stream. The most common encodings are UTF-8/16/32 but can limit the ability to support different languages.
Webapges contain links, how do we handle them effectively?
- Links describe the relationship between documents and they describe the referenced document.
- We can extract the anchor text and the URL of the link. The anchor text can be used as a term in the vocabulary.
- We typically give more weight to the anchor text for the referenced document.
How do we handle images?
- We may have to apply text extraction from images.
How do we handle different HTML Tags?
- We can assign higher weights to term occurrences in headlines, bold text, or text with emphasized rendering on the page.
Step 2: Split
Why we need to split the documents?
- For example, a 3 page document and a 300 page document, both are represented using single vector.
- Now, when documents is small, returning the whole document is a good idea but when the document is large, returning the whole document is not a good idea as it may not be relevant to the query.
- Takeaway: Splitting the documents into smaller pieces allows for a more precise retrieval at expense of more entries in the index.
- Now, when document is large, returning the whole document when the query terms match the document on first and last page of the document is not a good idea.
- Takeaway: Splitting documents into smaller chunks enforces proximity between query terms.
- Now, when documents is small, returning the whole document is a good idea but when the document is large, returning the whole document is not a good idea as it may not be relevant to the query.
There is no one-size-fits-all approach to splitting documents. It is a trade-off between more and smaller but semantically coherent parts of the documents and additional cost of storage and retrieval.
Method 1: Splitting the text into fixed-size chunks
- The document is splitted into chunks with a constant number of tokens, such as words or characters.
- Advantages: Straightforward and even size for all chunks simplifying normalization.
- Disadvantages: At the end of the chunk, we may have a partial term or sentence that belong to a sentence or paragraph in the document.
- Note: The number of tokens is a hyperparameter that requires training to achieve the best retrieval performance.
Method 2: Splitting the text with NLP techniques
- We define a minimum number of tokens and the text is splitted into sentences using NLP techniques. Then we merge sentences until the number of tokens is greater than the minimum number of tokens.
- Advantages: The chunks does not have partial sentences or terms.
- Disadvantages: We might still split the sentences that belong together.
- Note: The minimum number of tokens is a hyperparameter that requires training to achieve the best retrieval performance.
Method 3: Metadata/Structure based splitting
- The document is splitted based on the structure of the document, like chapters, sections, paragraphs, etc. The structure can be extracted from the meta information or the formatting information and these are used as chunk boundaries.
- Advantages: The chunks are semantically coherent.
- Disadvantages: There is difference in size of the the chunks and the structure may not be present in all documents.
Method 4: Semantic splitting
- The text is initially splitted into sentences and then the sentences are grouped into chunks based on the semantic similarity using machine learning techniques.
- Advantages: The chunks are semantically coherent.
- Disadvantages: The number of tokens in the chunks may vary and the semantic similarity is a hyperparameter that requires training to achieve the best retrieval performance.
Step 3: Tokenize
A token is a sequence of characters that represent a unit of meaning. Typically, tokens are words but we will explore other types of tokens in coming posts. The tokenization process is language dependent and can be complex for languages like Chinese, Japanese, etc.
- Character and fragment of words can be used as tokens. For example, if we have a document with the word "information", we can use "i", "n", "f", "o", "r", "m", "a", "t", "i", "o", "n" as tokens of 1 character.
- Words are primary tokens in most languages. We require additional processing to handle punctuation, special characters, etc. The challenge is to handle variations in the language like plural forms, verb conjugations, etc. Stemming and lemmatization are techniques to handle these variations.
- N-grams and Phrases are tokens that are sequences of n words. For example, "data science" is a bigram and "machine learning" is a bigram.
Why Lemmatization and Linguistic transformation are important?
- They are essential for matching query terms with the terms in the documents.
- Stemming reduces the vocabulary size and improves the retrieval performance.
How does Porter Stemmer work for English language?
- The Porter algorithm involve stripping suffixes from words. The algorithm contains 5 main steps with several sub-steps in each step.
- The Porter Stemmer can sometimes produce stems that aren’t exact dictionary forms but it is efffective in reducing the vocabulary size.
Step 4: Summarize
The final step is to summarize the extracted features into a concise representation. We represent each document as high dimmensional vector. Each dimmension corresponds to a term in the vocabulary and the value of the dimmension is the weight of the term in the document. The weight can be binary, frequency, or a more complex measure like TF-IDF.
Let's take an example of a very simple text document: "The cat sat on the mat." Our vocabulary might be: [the, cat, sat, on, mat].
The feature vector for the document could be represented as: [2, 1, 1, 1, 1].
This vector indicates that "the" appears twice, while all other terms appear once.
How do we do vocabulary control?
- We have earlier looked at stemming or lemmatization to reduce the vocabulary size.
- We can also remove stopwords, which are common words that do not carry much meaning like "the", "is", "and", etc.
- Inverse Document Frequency(IDF): This measures how important a term is across all documents. Considering the same example, If "cat" appears in 5 out of 100 documents, its IDF is log(100/5) = 1.30.
- Term Frequency-Inverse Document Frequency(TF-IDF): This is the product of the term frequency and the inverse document frequency. Continuing with the example, if the term frequency of "cat" is 3, then the TF-IDF is 3 * 1.30 = 3.90.
What are the different models for representing the documents?
-
Set-of-Words Model: This is a binary representation indicating the presence or absence of a term in the document.
- Example: For our previous example, the feature vector would be
[1, 1, 1, 1, 1].
- Example: For our previous example, the feature vector would be
-
Bag-of-Words Model: This is a frequency representation indicating the number of times a term appears in the document.
- Example: For our previous example, the feature vector would be
[2, 1, 1, 1, 1].
- Example: For our previous example, the feature vector would be
What is Zipf's Law and How we can determine the term discrimination power?
Zipf's law helps us understand term distribution and importance.
- Very frequent terms (like "the") are often less important for summarization.
- Very rare terms (like "photosynthesis") might be too specific.
- Terms in the middle range are most useful for summarization.
What was the another approach taken to quantify the term discrimination power?
Salton, Wong, and Yang's work provided a foundation for more effective indexing and retrieval techniques using space density computations.
- Term Discrimination Value: This value measures how well a term can differentiate between documents. A "good" index term is one that decreases the similarity between documents when it is used as an index term, thereby spreading out the document vectors in the space.
Let's understand the relationship between different terms:
TF-IDF and Discrimination Power
- Terms with high TF-IDF scores have high discrimination power.
- Both help identify terms that are important for distinguishing between documents.
IDF and Discrimination Power
- Highly correlated: rare terms (high IDF) have high discrimination power.
- Both help in identifying unique, content-rich terms.
TF-IDF and Retrieval
- TF-IDF is widely used in retrieval systems to rank documents.
- Documents with higher TF-IDF scores for query terms are considered more relevant.
Discrimination Power and Retrieval
- Terms with high discrimination power are valuable for improving retrieval accuracy.
- They help in distinguishing between relevant and non-relevant documents.
Conclusion
In this post, we discussed the fundamentals of text retrieval. We explored the steps of feature extraction from source documents during the indexing phase. We discussed the importance of extracting, splitting, tokenizing, and summarizing the documents. We also explored the different models for representing the documents and the importance of Zipf's law and term discrimination power.
Comments