
The Application Layer: Protocols
To properly learn something, we have to start at the beginning. We will learn one concept at a time, process it, and move to the next.
The goal is to consistently learn and absorb information while feeling engaged and not overwhelmed.
I have divided the application layer articles into two parts.
- Introduction to Application layer
- Application Layer Protocols
Goal of this article
We have just learned that network processes communicate with each other by sending messages into sockets. But how are these messages structured? What are the meanings of the various fields in the messages?
I will discuss the protocols available within the TCP/IP Five-layer network model application layer.
Protocols
An application-layer protocol defines how an application's processes, running on different end systems, pass messages to each other.
We will discuss the following application-layer protocol:
- HyperText Transfer Protocol (HTTP)
- Simple Mail Transfer Protocol (SMTP)
- Domain Name System (DNS)
HyperText Transfer Protocol (HTTP)
Hypertext Transfer Protocol (HTTP) is an application-layer protocol for transmitting hypermedia documents, such as HTML. HTTP was designed for communication between web browsers and servers, but HTTP can also be used for other purposes. HTTP follows a classical client-server model, with a client opening a connection to make a request, then waiting until it receives a response. HTTP is a stateless protocol, meaning the server does not keep any data (state) between two requests.
-
HTTP with Non-Persistent Connections - The non-persistent connection takes the connection time of 2RTT + file transmission time. It takes the first RTT (round-trip time) to establish the connection between the server and the client. The second RTT is taken to request and return the object. This case stands for a single object transmission. The connection is closed immediately after the client receives the object in a non-persistent connection.
-
HTTP with Persistent Connections - A persistent connection takes 2 RTT for the connection and transfers as many objects as wanted over this single connection. The persistent connection ensures the transfer of multiple objects over a single connection.
For example, Suppose ten images need to be downloaded from the HTTP server. The total time taken to request and download ten images in a non-persistent and persistent connection is:
Non-persistent => 2 RTT (Connection time) + 2 * 10 RTT = 22RTT
Persistent => 2 RTT (Connection time) + 10 RTT = 12RTTHTTP Message Format
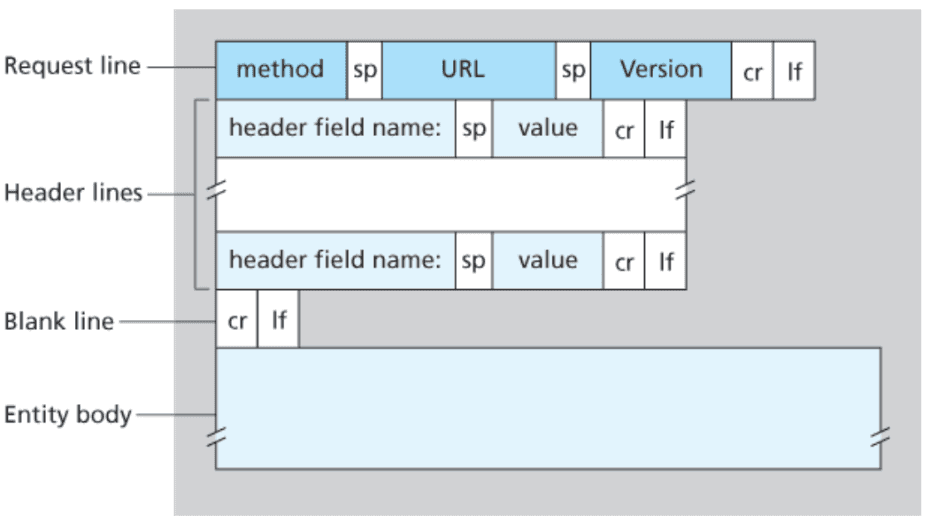
HTTP requests, and responses, share a similar structure and are composed of:
- A start-line describing the requests to be implemented or their status of whether successful or a failure. This start-line is always a single line.
- An optional set of HTTP headers specifying the request or describing the body included in the message.
- A blank line indicating all meta-information for the request has been sent.
- An optional
bodycontaining data associated with the request (like the content of an HTML form) or the document associated with a response. The start-line and HTTP headers specify the body's presence and its size.
Cookies
I mentioned above that an HTTP server is stateless. However, it is often desirable for a website to identify users because the server wishes to restrict user access or to serve content as a function of the user identity. For these purposes, HTTP uses cookies. Typically, an HTTP cookie is used to tell if two requests come from the same browser—keeping a user logged in, for example. It remembers stateful information for the stateless HTTP protocol.
Cookies are mainly used for three purposes:
-
Session management - Logins, shopping carts, game scores, or anything else the server should remember
-
Personalization - User preferences, themes, and other settings
-
Tracking - Recording and analyzing user behavior
Cookie technology has four components:
-
a cookie header line in the HTTP response message
-
a cookie header line in the HTTP request message
-
a cookie file kept on the user's end system and managed by the user's browser.
-
a back-end database at the Web site.
Web Caching
A Web cache, also called a proxy server, is a network entity that satisfies HTTP requests on behalf of an origin Web server.
A cache is both a server and a client at the same time. It is a server that receives requests and sends responses to a browser. When it sends requests to and receives responses from an origin server, it is a client.
There are several advantages to reusability. First, since there is no need to deliver the request to the origin server, the closer the client and cache are, the faster the response will be. The most typical example is when the browser itself stores a cache for browser requests.
Also, when a response is reusable, the origin server does not need to process the request — so it does not need to parse and route the request, restore the session based on the cookie, query the DB for results, or render the template engine. That reduces the load on the server.
Proper operation of the cache is critical to the health of the system.
We've seen the format of HTTP messages and the actions taken by the Web client and server as these messages are sent and received. We have gone through infrastructure, including caches and cookies, all of which are tied somehow to the HTTP protocol.
Simple Mail Transfer Protocol (SMTP)
-
SMTP is the principal application-layer protocol for Internet electronic mail.
-
It uses TCP's reliable data transfer service to transfer mail from the sender's mail server to the recipient's mail server.
-
SMTP has two sides:
- Client-side, which executes on the sender's mail server.
- Server-side, which executes on the recipient's mail server.
-
The client and server sides of SMTP both run on every mail server. When a mail server sends mail to other mail servers, it acts as an SMTP client. When a mail server receives mail from other mail servers, it acts as an SMTP server.
-
SMTP restricts all mail messages' body (not just the headers) to simple 7-bit ASCII.
-
The client SMTP (running on the sending mail server host) has TCP establish a connection to port 25 at the server SMTP (running on the receiving mail server host).
-
SMTP uses a persistent connection.
-
SMTP is a push protocol that means the sending mail server pushes the data onto the receiving mail server by initiating a TCP connection.
But there is still one missing piece to the puzzle! How does a recipient running a user agent obtain the messages sitting in a mail server within the recipient's ISP? Note that the user agent can't use SMTP to obtain the messages because obtaining the messages is a pull operation, whereas SMTP is a push protocol.
The puzzle is completed by introducing a special mail access protocol that transfers messages from the recipient's mail server to the user agent.
Post Office Protocol (POP3)
-
POP3 begins when the user-agent (the client) opens a TCP connection to the mail server (the server) on port 110.
-
With the TCP connection established, POP3 progresses through three phases: authorization, transaction, and update
- Authorization: The user agent sends a username and a password (in the clear) to authenticate the user.
- Transaction: The user agent retrieves messages, and the user agent can mark messages for deletion, remove deletion marks, and obtain mail statistics.
- Update: This phase occurs after the client has issued the quit command, ending the POP3 session, and the mail server deletes the messages marked for deletion.
Internet Mail Acess Protocol (IMAP)
- An IMAP server associates each message with a folder. When a message first arrives at the server, it
is associated with the recipient's INBOX folder.
-
The IMAP protocol provides commands to allow users to create folders and move messages from one folder to another.
-
The IMAP protocol provides commands that allow users to search remote folders for messages matching specific criteria.
-
The IMAP server maintains user state information across IMAP sessions—for example, the names of the folders and which messages are associated with which folders.
-
The IMAP protocol has commands that permit a user agent to obtain components of messages which proves helpful when there is a low-bandwidth connection between the user agent and mail server.
Web-Based E-Mail
- When a sender wants to send an e-mail message, the e-mail message is sent from the browser to the mail server over HTTP rather than SMTP. However, the recipient's mail server still sends and receives messages from other mail servers using SMTP.
Domain Name System (DNS)
Just as humans can be identified in many ways, so can Internet hosts. One identifier for a host is its hostname. Hostnames are mnemonic and are therefore appreciated by humans. Furthermore, because hostnames can consist of variable length alphanumeric characters, they would be difficult to process by routers, and therefore hosts are also identified by IP addresses.
We have just seen that there are two ways to identify a host - by a hostname and an IP address. People prefer the more mnemonic hostname identifier, while routers prefer fixed-length, hierarchically structured IP addresses.
Domain Name System is a directory service that translates hostnames to IP addresses. The DNS is:
-
A distributed database implemented in a hierarchy of DNS servers.
-
An application-layer protocol that allows hosts to query the distributed database.
-
The DNS protocol runs over UDP and uses port 53.
DNS Services
- Host Aliasing - A host with a complicated hostname can have one or more alias names, and the hostname is called a canonical hostname. Alias hostnames,
when present, are typically more mnemonic than canonical hostnames. An application can invoke DNS to obtain the canonical hostname for a supplied alias hostname as well as the IP address of the host.
-
Mail Server Aliasing - DNS can be invoked by a mail application to obtain the canonical hostname for a supplied alias hostname as well as the IP address of the host.
-
Load Balancing - DNS performs load distribution among replicated servers, such as
replicated Web servers. For replicated Web servers, a set of IP addresses is thus associated with one canonical hostname. The DNS database contains this set of IP addresses. When clients make a DNS query for a name mapped to a set of addresses, the server responds with the entire set of IP addresses and rotates the ordering of the addresses within each reply.
DNS Functionality
The DNS uses a large number of servers, organized hierarchically and distributed around the world. No single DNS server has all the mappings for all the hosts on the Internet. Instead, the mappings are distributed across the DNS servers. To a first approximation, there are three classes of DNS servers:
-
Root DNS servers: There are over 400 root name servers scattered all over the world. Root name servers provide the IP addresses of the TLD servers.
-
Top-level domain (TLD) DNS servers: For each of the top-level domains such as com, org, net, edu, and gov, and all of the country top-level domains such as uk, fr, ca, and jp, there is TLD server (or server cluster). TLD servers provide the IP addresses for authoritative DNS servers.
-
Authoritative DNS servers: Every organization with publicly accessible hosts (such as Web servers
and mail servers) on the Internet must provide publicly accessible DNS records that map the names of those hosts to IP addresses.
The client first contacts one of the root servers, which returns IP addresses for TLD servers for the top-level domain. The client then contacts one of these TLD servers, which returns the IP address of an authoritative server for the requested hostname. Finally, the client contacts one of the authoritative servers, which returns the IP address for the hostname.
DNS Caching
-
If a hostname/IP address pair is cached in a DNS server and another query arrives at the DNS server for the same hostname, the server can provide the desired IP address even if it is not authoritative for the hostname. Because hosts and mappings between hostnames and IP addresses are by no means permanent, DNS servers discard cached information after a period (often set to two days).
-
A local DNS server can also cache the IP
addresses of TLD servers, thereby allowing the local DNS server to bypass the root DNS servers in a query chain. In fact, because of caching, root servers are bypassed for all but a tiny fraction of DNS queries.
DNS Records
The DNS servers that together implement the DNS distributed database store resource records (RRs), including RRs that provide hostname-to-IP address mappings. Each DNS reply message carries one or more resource records.
A resource record is a four-tuple that contains the following fields:
(Name, Value, Type, TTL)- TTL is the time to live of the resource record; it determines when a resource should be removed from a
cache.
The meaning of Name and Value depend on Type.
-
If
Type=A, thenNameis a hostname, andValueis the IP address for the hostname. Thus, aType Arecord provides the standard hostname-to-IP address mapping. -
If
Type=NS, thenNameis a domain, andValueis the hostname of an authoritative DNS server that knows how to obtain the IP addresses for hosts in the domain. This record routes DNS queries further along in the query chain. -
If
Type=CNAME, thenValueis a canonical hostname for the alias hostnameName. This record
can provide querying hosts the canonical name for a hostname.
- If
Type=MX, thenValueis the canonical name of a mail server with an alias hostname Name.
DNS Messages
- DNS has a
queryandreplymessages.
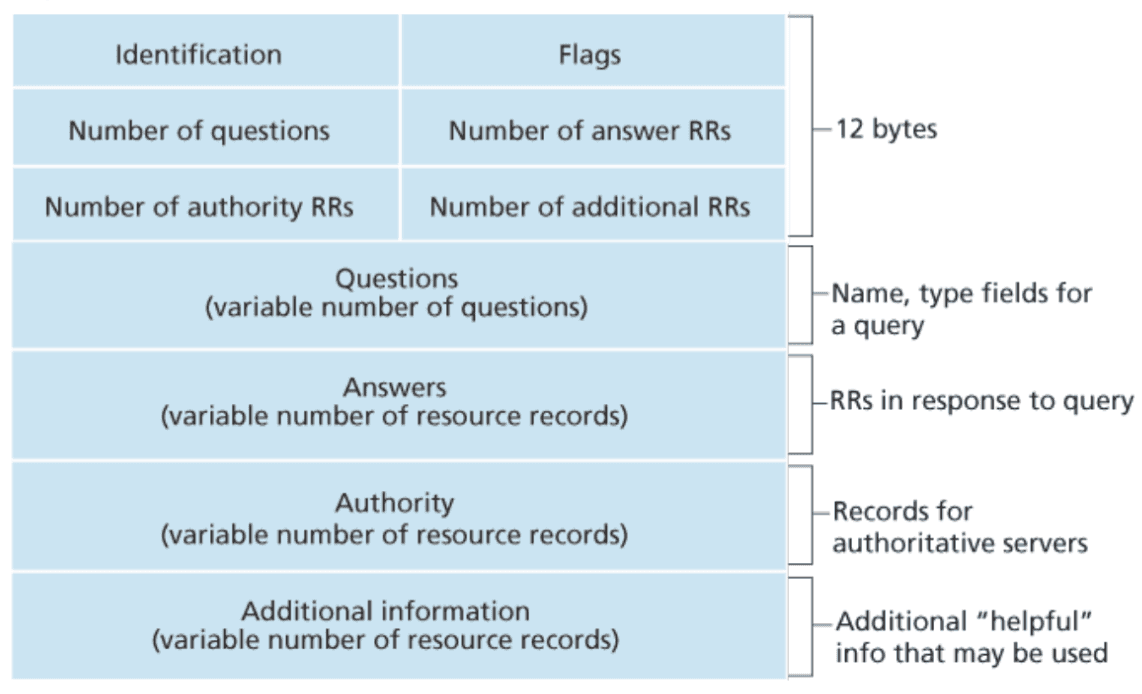
- The first 12 bytes are the header section, which has several fields.
- The first field is a 16-bit number that identifies the query. This identifier is copied into the reply message to a query, allowing
the client to match received replies with sent queries. There are several flags on the flag field. - A 1-bit query/reply flag indicates whether the message is a query (0) or a reply (1). - A 1-bit authoritative flag is set in a reply message when a DNS server is an authoritative server for a queried name. - A 1-bit recursion-desired flag is set when a client (host or DNS server) desires that the DNS server perform recursion when it doesn't have the record. - A 1-bit recursion-available field is set in a reply if the DNS server supports recursion. In the header, there are also four number-of fields. - These fields indicate the number of occurrences of the four types of data sections that follow the header.
-
The question section contains information about the query that is being made. This section includes
- A name field that contains the name that is being queried
- A type field indicates the type of question being asked about the name—for example, a host address associated with a name(Type A) or the mail server for a name (Type MX).
-
In a reply from a DNS server, the answer section contains the resource records for the name that was queried initially. A reply can return multiple RRs in the answer since a hostname can have multiple IP addresses.
-
The authority section contains records of other authoritative servers.
-
The additional section contains other helpful records. For example, the answer field in reply to an
MX query contains a resource record providing the canonical hostname of a mail server. The additional section contains a Type A record providing the IP address for the canonical hostname of the mail server.
DNS Records Insertion
A registrar is a commercial entity that verifies the uniqueness of the domain name, enters the domain name into the DNS database, and collects a fee for its services.
When you register the domain name with some registrar, we also need to provide the registrar with the names and IP addresses of primary and secondary authoritative DNS servers.
More recently, an UPDATE option has been added to the DNS protocol to allow data to be dynamically added or deleted from the database via DNS messages.
Did you find this post helpful so far?
I would be grateful if you let me know by commenting below. Means a lot to me!
Sign up to get updates when I write something new. No spam ever.
Comments