
Text Retrieval Methods
Large Language Models(LLMs) is a hot topic after the release of GPT-3 and has seen a fast paced adoption across industries.
Text retrieval is a fundamental building block of modern search algorithms and application powered by LLMs. Last post explored the fundamentals of text retrieval.
In this post, we explore various retrieval methods, examining their pros and cons. We will use the following notation throughout this post:

Standard Boolean Model
-
Boolean retrieval model is a simple model based on boolean logic and set theory.
-
Documents are represented as sets of words which is a binary representation of the presence or absence of words in the document.
-
Queries are designed as boolean expressions of terms and operators like AND, OR, NOT.
-
The retrieval is based on binary decision of whether a document satisfies the query or based on set operations like intersection and union.
-
Advantages
- Simple model with clear query semantics.
- Easy to implement and user-friendly.
- Fast evaluation with set operations enables efficient retrieval, even for large collections.
- Boolen expression offer precise control over the retrieval process, infuencing the result size.
- Easy to extend with additional filters over metadata of documents.
-
Disadvantages
- Lack of ranking of documents based on relevance.
- No Partial matching of terms.
- Users need to be familiar with boolean logic to construct effective queries.
- This model represent data retrieval more than information retrieval.
Extended Boolean Model
-
Extended Boolean model is an extension of the standard boolean model.
- It indroduces scores for ranking, considering weight for terms and term occurence in the document.
- It allows for partial matching of terms, by considering the presence of terms in the document.
-
Documents are represented as bag of words assigning normalized vectors (𝒅𝑖) to documents using term occurrences and inverse document frequency (𝑖𝑑𝑓). Normalization ensures values within the vector components range between 0 and 1.
-
Queries remain boolean expressions similar to the standard boolean model.
-
The retrieval is based on the similarity
𝑠𝑖𝑚(𝜏, 𝐷𝑖)between the query and the document. -
Advantages:
- Simple model with clear query semantics.
- Easy to implement and user-friendly.
- Solid performance though query evaluation is heuristic.
- With Inverted file method, similarity computation can be efficient.
- Partial matching of terms allows for more flexible retrieval.
- Terms are treated differently based on term occurence and discrimination power.
-
Disadvantages:
- Heuristic similarity lacks clear theoretical foundation.
- Complex queries can be difficult to construct.
Vector Space Retrieval Model
-
The vector space retrieval model treats documents and queries as vectors in a high-dimensional feature space. It employs vector-based similarity metrics for ranking.
-
A document 𝐷𝑖 is represented as a vector 𝒅𝑖 , utilizing idf-weighted term frequencies. Unlike the extended Boolean models, we refrain from normalizing the term frequencies. All document representations can be merged into the term-document matrix 𝐀.
-
Queries are depicted as sparse vectors, denoted as 𝒒 following identical processing steps and vocabulary use as documents.
-
The retrieval can be done in two ways:
-
The inner vector product uses the dot-product between the query and document vector. When applied to the entire collection, we multiply the term-document matrix by the query vector and then rank documents based on decreasing similarity values.
-
The cosine measure calculates the angle between document and query vectors. It implies that documents need to contain query terms for high scores. Absence of query terms widens the angle between the vectors, leading to lower scores. Similar to the inner vector product, scores for all documents can be calculated through matrix-vector multiplications. For this, we normalize the query vector by its size and introduce a diagonal matrix 𝐋 with inverse document lengths to dynamically normalize document vectors.
-
Q: Explain the concept of vector normalization and its relationship to cosine similarity in information retrieval?
-
Vector normalization is a process that converts vectors to unit length (length of 1) while preserving their directional properties. This is particularly important in document comparison because:
- It eliminates the bias of document length
- Makes documents directly comparable regardless of size
- Simplifies the calculation of similarity measures like cosine similarity
-
Effect on Similarity Calculations
-
Before Normalization:
- Longer documents tend to have larger term frequencies
- Raw inner product favors longer documents
- Results are biased by document length
-
After Normalization:
- All vectors have length 1
- Only direction matters, not magnitude
- Cosine similarity equals dot product of normalized vectors
-
Benefits
- Focus shifts to term distribution rather than frequency
- Similar documents have similar scores regardless of length
- Prevents bias towards longer documents
-
-
Advantages:
- Extremely simple and intuitive query model.
- Term weights have a good impact on the scores and differentiate between query terms, e.g., reducing the impact of stop words in the query.
- Easy to implement and highly efficient in calculation.
- Naturally supports partial match queries, and documents do not have to include all query terms for high similarity values.
-
Disadvantages:
- Heuristic similarity scores with little intuition why they work well.
- The similarity measures are not robust and can be biased by authors (spamming of terms).
- Main assumption of retrieval model is independence of terms which may not hold true in typical scenarios like synonyms, homonyms, etc.
Probabilistic Retrieval Model (Binary Independence Model)
-
The Binary Independence Model (BIR) is a straightforward approach grounded in several key assumptions:
- Term frequency does not matter (utilizing a set-of-words document model)
- Terms are independent of each other (consistent with the previous models)
- Terms absent from the query do not influence ranking (if a term is absent from the query, it’s assumed to be equally distributed among relevant and non-relevant documents)
-
Initial Probability Estimation
- System makes initial guesses about term relevance.
- Uses available relevance information if any exists.
-
Iterative Refinement
- Probabilities are updated based on relevance feedback.
- System learns from user interactions.
- Rankings are adjusted accordingly.
-
Advantages:
- The BIR model establishes similarity values on a probabilistic basis through basic assumptions.
- Document ranking depends on the likelihood of being relevant for the query.
- Only query terms are necessary for similarity calculations, and the inverted file method offers efficient evaluation.
- The model is robust and can be extended with relevance feedback.
-
Disadvantages:
- The basic assumptions of the BIR model may not always be valid.
- The document ranking in BIR doesn't consider term frequencies or the discrimination power of terms.
- The user feedback loop can be complex and requires a well-designed user interface.
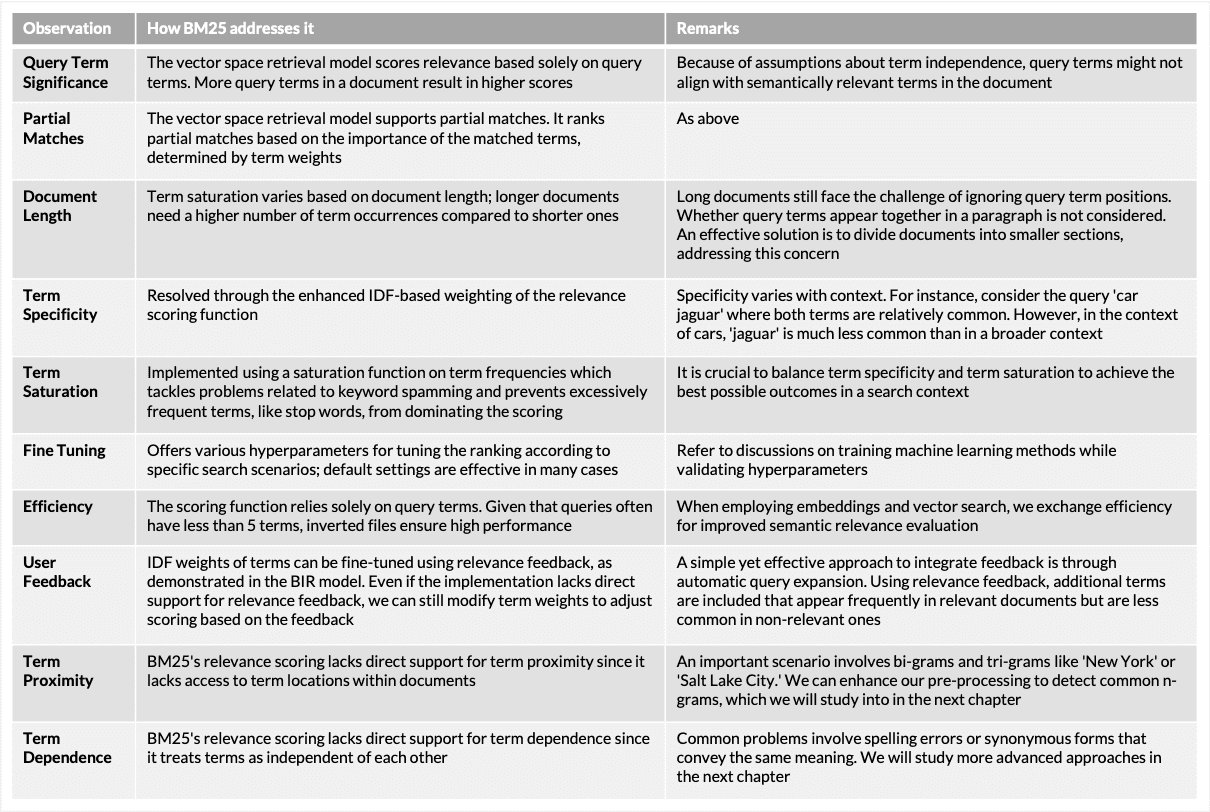
Before we move ahead, there are some limitation of above discussed models which led to the development of more advanced models like Okapi BM25 and Language Models. Researchers developed these models to address the limitations of the existing models and improve relevance assessment based on these key aspects:
- Query Term Significance: the presence or absence of query terms is crucial for relevance assessment
- Partial Matches: not all relevant documents contain every query term
- Document Length: longer documents have more terms, but shorter relevant ones should score well too
- Term Specificity: rare words often carry more meaning than common ones
- Term Saturation: while term frequency matters, overly frequent terms should not dominate
- Fine Tuning: flexibility to adjust ranking based on search context
- Efficiency: efficient retrieval and relevance assessment are essential
- User Feedback: if available, integration of user feedback for improved search quality
- Term Proximity: closeness of query terms in a document may indicate higher semantic relevance
- Term Dependence: recognizing term dependencies, like matching query 'animals’ to 'cats' or 'dogs’ in documents
Okapi Best Match 25 (BM25)
-
BM25 builds on the vector space model before enhancing it with a probabilistic approach for relevance evaluation.
-
BM25 addresses the above mentioned observations or provides ways to consider them.
-
Term Frequencies
- BM25 uses a saturation function with a hyperparameter
kto prevent overly frequent terms from dominating the ranking. - The saturation function ensures that term frequency has a diminishing impact on the score. Typically,
𝑘 ∈ [1, 2]with Lucene using𝑘 = 1.2.
- BM25 uses a saturation function with a hyperparameter
-
Document Length
- Lengthier documents include more terms and should saturate at a slower rate than shorter ones that might not have as many terms.
- BM25 introduces a document length normalization factor
bto account for the varying lengths of documents. 𝑏 ∈ [0,1]is a new hyperparameter that steers the impact of document length. Higher values prefer shorter documents.- The normalization factor is calculated based on the average document length
adlin the collection. 𝑎𝑑𝑙does not have to be the accurate average length of documents. Rather, we can consider it as another hyperparameter to define what ‘long’ / ‘short’ means.
We can say that BM25 improves upon simpler models by incorporating document length normalization and term frequency saturation.
In fundamental formulation, BM25 encompasses three hyperparameters (𝑘, 𝑏, 𝑎𝑑𝑙) that allow fine-tuning the scoring function to match the requirements of the search context.
Conclusion
In this post, we explored various text retrieval methods, starting from the standard boolean model to the advanced Okapi BM25 model. Each model has its own set of advantages and disadvantages, and researchers have developed these models to address the limitations of the existing models and improve relevance assessment.
Comments